




Have you ever thought that programming may have changed completely? Developers are moving from simply using AI tools to view AI as a new foundation for building software. This is not a minor adjustment, but a complete paradigm shift. Think about it, the core concepts we have always been accustomed to – version control, templates, documents, and even the concept of “users” are being redefined because of AI agent-driven workflows.
It reminds me of the transition from a carriage to a car. At first, people just treated cars as “a carriage without a horse”, but soon realized that the entire transportation system needed to be rethinked. Roads, regulations, and urban layout have all changed. Now we are going through a similar transformation. AI agents are both collaborators and consumers, which means we need to redesign everything.
You will see a major shift in basic development tools, such as propt can now be processed like source code, dashboards can have conversations, and documents are written not only for humans, but also for machines. Model context protocol (MCP) and AI native IDE point to a deep reshaping of the development loop itself—we are not only programming in different ways, but also designing tools for a world where AI agents are fully involved in software loops.
It’s like when PCs emerged in the 1970s, we moved from host terminals to personal workstations. At that time, no one could imagine that everyone would have a computer. Now, we are facing a similar turning point: every developer will have his own AI agent team.
Today we will talk about nine very forward-looking developer trends. Although they are still in their early stages, they are all based on real pain points, showing us what the future may look like. These trends include rethinking versioning of AI-generated code to large language model-driven user interfaces and documentation.
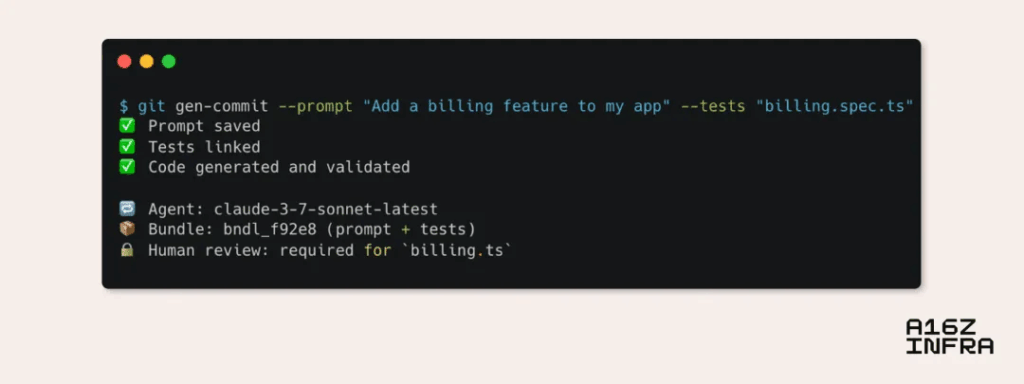
AI native Git: Reshape version control for AI agent
The idea might sound crazy at first, but listen to me. Now that AI agents are increasingly writing or modifying most of the application code, the things that developers care about are beginning to change. We no longer worry about what code we write one by one, but rather care whether the output runs as expected. Have the changes passed the test? Does the application still work as expected?
There is a very interesting phenomenon here, which I call “the upward movement of the truth”. In the past, the source code was the truth. Now, the combination of propt and tests is the truth. Think about it, if I told you “write a to-do list application with React”, and then the AI agent generates 1,000 lines of code, do you really care how each line of code is written? Or do you care more about whether it can be used?
This subverts a long-standing mindset. Git is designed to track the precise history of handwritten code, but with programming AI agents, this granularity becomes less meaningful. Developers usually don’t review every difference—especially when changes are large or automatically generated—they just want to know if the new behavior meets the expected results.
This reminds me of a basic principle of software engineering: abstraction. We are always looking for the right abstraction layer. Assembly language is too low-level, so we have a high-level language. The machine code is too difficult to understand, so we have a compiler. Now, line by line code may be too low-level, and we need new abstractions.
As a result, Git SHA – once a standard reference for “codebase state” – began to lose some semantic value. SHA just tells you something has changed, but doesn’t tell you why or whether it works. In an AI-first workflow, a more useful unit of truth might be a combination of a prompt of the code and a test that validates its behavior.
In this world, your application’s “state” may be better represented by generated inputs (prompt, specification, constraints) and a set of passed assertions rather than a frozen commit hash. Imagine that future developers might say, “Show me the test coverage of propt v3.1” instead of “Show me the diff of commit SHA abc123”.
In fact, we might end up tracking the propt+ test packages as a unit that is versionable in itself, and Git is downgraded to tracking these packages, not just the original source code. This is what I call “intention-driven version control”. We are not in version control code, but in version control intention.
Going further, in an AI agent-driven workflow, the source of truth may be shifted upstream to propt, data architecture, API contracts, and architectural intent. Code becomes a byproduct of these inputs, more like compiled artifacts than manually written source code. In this world, Git started to act less as a workspace and more as an artifact log—a place that tracks not only what changes, but also why and by whom.
Think about this scenario: You are debugging a question. You are not looking for “who changed this line of code when”, but asking “what AI agent made this decision based on what propt, and where did the human reviewer sign and confirm it?” This is the future code archaeology.
Dashboard evolution: synthetic AI-driven dynamic interface
This is a trend that I think is seriously underestimated. For many years, dashboards have been the main interface for interacting with complex systems, such as observability stacks, analytics platforms, cloud consoles (think AWS), and so on. But their designs often suffer from UX overloads: Too many knobs, charts, and tabs force users to both look for information and figure out how to handle it.
I have a friend who is an operation and maintenance engineer and he told me that he spent half of his time switching between various dashboards trying to piece together what was wrong with the system. This is completely a problem of information overload. It is not the lack of data, but the amount of data is too much and I don’t know how to organize it.
Especially for non-advanced users or cross-team use, these dashboards can become daunting or inefficient. Users know what they want to achieve, but don’t know where to look or what filters to apply to get to their destination. It’s like finding a specific screwdriver in a huge toolbox, but all the tools are almost the same.
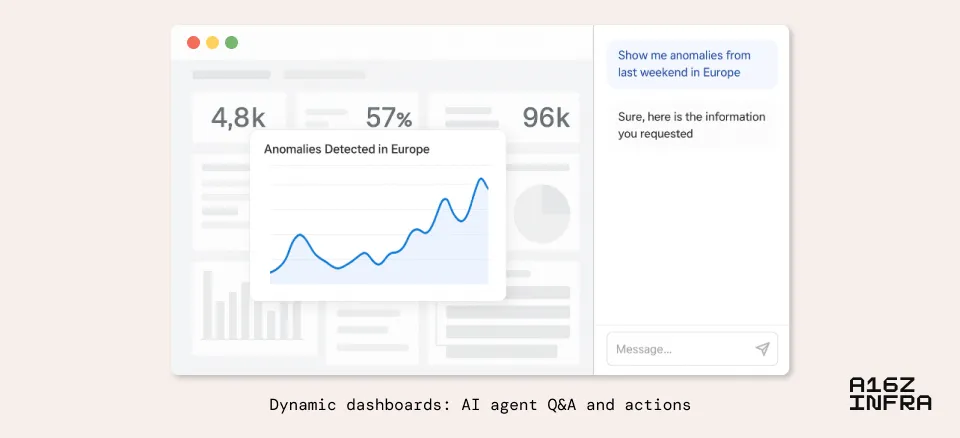
The latest generation of AI models offers a potential transformation. Instead of using them as stiff canvas, we can add search and interaction features to the dashboard. Now LLM can help users find the right control (“Where can adjust the current limit settings of this API?”); combine the entire screen data into easy-to-understand insights (“Summary of error trends in all services in the pre-release environment within the past 24 hours”); and emerge unknowns (“Based on your understanding of my business, generate a list of metrics that I should pay attention to this quarter”).
There is a cool concept here, which I call “data display of context culture”. Traditional dashboards are static: they display fixed metrics in a fixed way. But an AI-powered dashboard can reconfigure itself based on your current tasks, your role, and even your past behavior patterns.
We have seen technical solutions like Assistant UI that enable AI agents to use React components as tools. Just as content becomes dynamic and personalized, the UI itself can become adaptive and conversational. In front of a natural language-based interface, a purely static dashboard may quickly appear outdated, which is reconfigured according to user intentions.
For example, a user could say “showing anomalies in Europe last weekend” and the dashboard would be reshaped to display the view, including summarized trends and related logs. Or, more powerfully, “Why did our NPS score drop last week?”, AI might extract investigative sentiment, associate it with product deployment, and generate a brief diagnostic narrative.
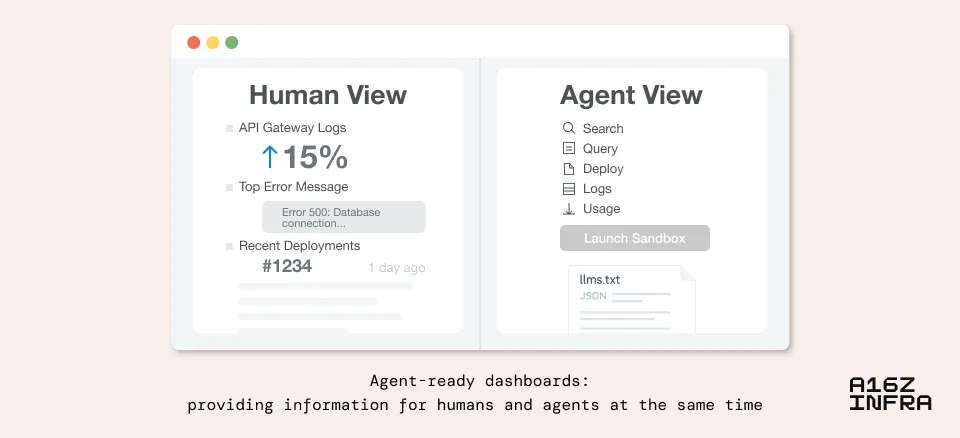
But there is a deeper transformation here: dashboards are no longer just designed for humans. AI agents also need to “see” and “understand” the system state. This means we may need a dual-mode interface: a human-friendly, an agent-friendly. Think of this scenario: an AI agent is monitoring your system, it does not require beautiful charts, it requires structured data and executable context.
It’s like designing for different senses: humans see with their eyes, agents “perceive” with their APIs. Future dashboards may need to serve both “species” at the same time, which is a completely new design challenge.
Documentation is becoming a mix of tools, indexes, and interactive knowledge bases
This change made me very excited. Developers’ behavior in documentation is changing. Rather than reading the directory or scanning from top to bottom, the user now starts with a question. The psychological pattern is no longer “let me study this norm”, but “reorganize this information the way I like.”
I remember when I first started programming, I would spend hours reading API documentation from beginning to end. What about now? I open the document and search directly for what I want, or ask the AI ”How to use this library to do X”. This is not laziness, but the evolution of efficiency.
This subtle shift—from passive reading to active queries—is changing what a document needs to be. They are no longer just static HTML or markdown pages, but are becoming interactive knowledge systems, powered by index, embedding, and tool-aware AI agents.
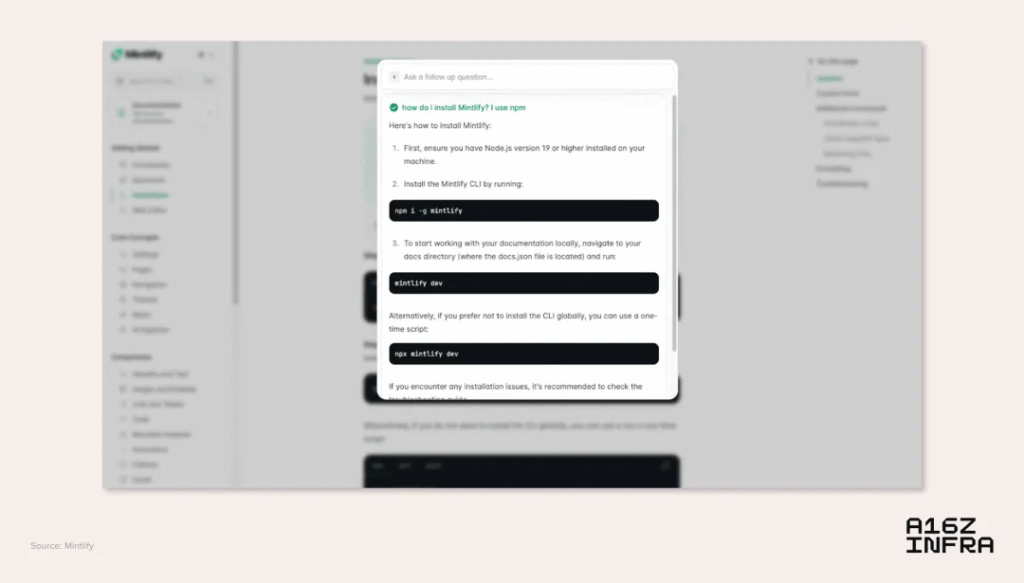
So we see the rise of products like Mintlify, which not only structure documents into semantically searchable databases, but also serve as context sources for cross-platform programming AI agents. Mintlify pages are now often referenced by AI programming agents—whether in AI IDE, VS Code extensions, or terminal agents—because the programming agent uses the latest documentation as the basis context for generation.
This changed the purpose of the document: they no longer serve human readers but also AI agent consumers. In this new dynamic, the document interface becomes an AI agent instruction. It not only exposes the original content, it also explains how to use a system correctly.
There is a very interesting trend here, which I call “dual character of documents”. Human readers need context, examples, and explanations. An AI agent requires structured data, clear rules and executable instructions. Good documentation needs to meet both needs.
Future documents may have three levels: the human reading layer (with storyline and explanation), the AI consumption layer (structured and precise), and the interaction layer (allowing inquiry and exploration). It’s like designing textbooks for different learning styles, but this time it’s designed for different “thoughts”.
From template to generation: vibe coding replaces create-react-app
This trend reminds me of the transition from the Industrial Revolution to the Digital Revolution. In the past, starting a project means choosing a static template, such as a boilerplate GitHub repository or CLI like create-react-app, next init, or rails new. These templates serve as scaffolding for new applications, providing consistency but lacking customization.
Developers either follow any default values provided by the framework or risk a lot of manual refactoring. It’s like standardized production in the industrial age: you can have any color of the car as long as it’s black.
Now, with the advent of text-to-app platforms like Replit, Same.dev, Loveable, Convex’s Chef and Bolt, and AI IDEs like Cursor, this dynamic is changing. Developers can describe what they want (such as “a TypeScript API server with Supabase, Clerk, and Stripe”) and get a custom project scaffolding in seconds.
The result is a launcher that is not universal but personalized and purposeful, reflecting the developer’s intentions and the technology stack they choose. It’s like moving from industrial production to large-scale customization. Each project can have a unique starting point instead of starting with the same template.
This unlocks a new distribution mode in the ecosystem. Rather than letting a few frameworks sit with long tails, we may see a wider distribution of composable, stack-specific generations where tools and architectures are dynamically mixed and matched. This is more about describing a result, and AI can build a stack around it, rather than selecting a framework.
But there is an interesting side effect here, which I call “framework democratization”. Previously, choosing a framework was a major decision because the switching cost was high. Now, frame selection becomes more like choosing what to wear today: it can be changed at any time.
Of course, this also brings new challenges. Standardization has its advantages – teamwork is easier, troubleshooting is easier, and knowledge spreads faster. But as AI agents are able to understand project intentions and perform large-scale reconstructions, the cost of experiments is significantly reduced.
This means we may see a more fluid ecosystem of technology stacks where choice is no longer a permanent decision but a starting point for evolution.

Beyond.env: Manage secrets in an AI agent-driven world
This is a question that many people ignore but is extremely important. For decades, .env files have been the default way for developers to manage secrets locally (such as API keys, database URLs, and service tokens). They are simple, portable, and developer-friendly. But in the AI agent-driven world, this paradigm begins to collapse.
Think about this scenario: you have an AI agent writing code for you, and it needs to be connected to your database. Do you really want to give the database password directly? If so, who is responsible for data breaches? AI agent? you? Or is it a provider of AI agent?
When an AI IDE or an AI agent writes code, deploys services, and coordinates the environment on our behalf, it is no longer clear who owns .env. More importantly, the traditional concept of “environmental variables” itself may be outdated. What we need is a secret management system that can give precise permissions, auditable, and revocable.
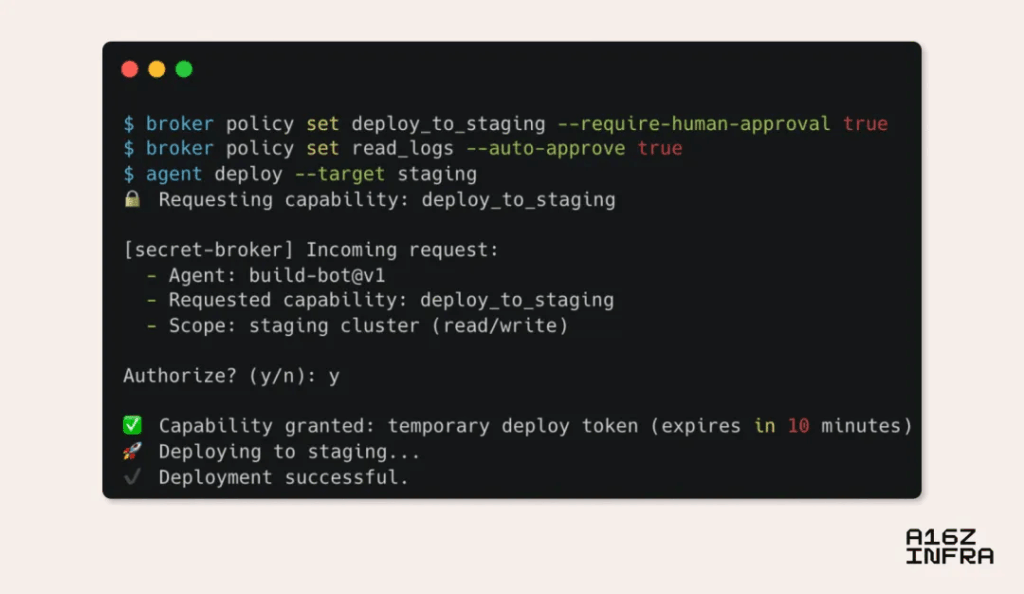
We saw some signs of what might look like. For example, the latest MCP specification includes an OAuth 2.1-based authorization framework that implies a possible shift toward providing AI agents with scoped, revocable tokens instead of original secrets. We can imagine a scenario where an AI agent does not get your actual AWS key, but rather a short-term credential or capability token that allows it to perform a narrowly defined operation.
Another way this may develop is through the rise of local secret agents—a service that runs on your machine or with your application, acting as an intermediary between AI agents and sensitive credentials. A proxy can request access to a capability (“Deploy to Pre-Publish” or “Send logs to Sentry”), while the proxy decides whether to grant it–real-time, and fully auditable.
I call this trend “capacity-oriented security.” Instead of giving AI agent keys (secrets), we give them permissions (capacity). It’s like moving from “trust but validation” to “zero trust but enable”.
Future secret management may look more like a permission system, with each operation having a clear scope, every AI agent having a clear role, and all accesses are recorded and audited. This is not only safer, but also more in line with how AI agents work: they don’t need to know everything, they just need to know what they need to accomplish their tasks.
Accessibility as a universal interface: viewing the application through the eyes of LLM
This trend reminds me of the “unexpected innovation” theory. We are beginning to see a new class of applications (such as Granola and Highlight) that request access to accessibility settings on macOS, not for traditional accessibility use cases, but for AI agents to observe and interact with the interface. But this is not a hack: it is a sign of a deeper transformation.
The Accessibility API was originally built to help users with vision or movement disorders navigate digital systems. Now, these same APIs are becoming the common language for AI agents to understand and control digital environments. It’s like Braille unexpectedly becoming the way robots read the world.
Think about this: Accessibility API has solved the problem of “how to make machines understand the human interface”. They provide semantic element descriptions: this is a button, this is the input box, this is the link. For AI agents, this is the perfect data structure.
Here is a deep insight: we are always looking for how to make AI agents interact with the human world, but the answer may be right in front of us. Accessibility technology has been standardized, has been implemented in all mainstream operating systems, and has undergone more than ten years of practical testing.
If carefully expanded, this could become a common interface layer for AI agents. Instead of clicking on pixel positions or crawling the DOM, an AI agent can semantically observe an application like assistive technology. Accessibility trees have exposed structured elements such as buttons, titles, and input boxes. If extended with metadata (such as intentions, roles, and functions), this could become the first type of interface for AI agents, allowing them to perceive and operate applications purposefully and accurately.
In fact, there are several possible development paths in this direction:
The first is context extraction, we need a standard way to enable LLM agents using accessibility or semantic APIs to query what is on the screen, what it can interact with, and what the user is doing. Imagine that an AI agent can say “tell me all the clickable elements on this screen” or “whether the user is now”, and get a structured answer immediately.
The second is intent execution. Instead of expecting the AI agent to manually concatenate multiple API calls, expose a high-level endpoint and let it declare the target (“add item to cart, select the fastest delivery”) and let the backend calculate the specific steps. It’s like telling the driver to “take me to the airport” instead of giving every turn command.
The third is the backup UI of LLM. The barrier-free function provides an alternate UI for LLM. Any application that exposes the screen becomes available to the AI agent, even if it does not expose the API. For developers, this hints about a new “rendering layer”—not just a visual or DOM layer, but a context accessible to the AI agent, which may be defined by structured annotations or accessibility-first components.
These three directions point to a future together: applications are no longer designed for the human eye, but also for the AI ”eye”. Each interface element carries rich semantic information, describing not only what it looks like, but also what it can do, and how it can be used.
This leads to an interesting idea: What if we take accessibility design as the standard for “machine readability”? Every new UI element, every new interactive mode, takes machine understanding from the very beginning. This benefits not only people with disabilities, but also AI agents.
In the future, we may see a “dual design” trend: not only for humans, but also for AI agents. The accessibility principle may become a bridge between the two. It’s like designing a language for a multicultural world: considering not only native speakers, but also learners and translators.
The rise of asynchronous AI agent work
This trend reflects a fundamental shift in how you work. As developers begin to work more smoothly with programming AI agents, we see a natural transition to asynchronous workflows, which run in the background, pursue parallel worker threads, and report back as progress is made.
This reminds me of the transition from synchronous programming to asynchronous programming. At the beginning, the program is synchronized: finish one thing, and then do the next thing. Then we found that waiting is a waste of time, and concurrency is the king. Now, we are undergoing the same transformation at the level of human-computer collaboration.
This interactive mode starts to look less like pairing programming, more like task orchestration: you delegate a target to let the AI agent run, check it later. It’s like you have a very capable intern and you can give him a project and let him do it and then you focus on other things.
The point is that it’s not just an uninstall effort; it also compresses coordination. Contacting another team to update configuration files, classify errors, or refactor components, developers are increasingly able to assign this task directly to an AI agent that acts according to their intentions and executes in the background.
This change has a deep meaning: we are moving from synchronous collaboration to asynchronous symphony. Traditional software development is like a face-to-face meeting: everyone is present at the same time, discussing in real time. The new mode is more like a distributed orchestra performance: each performer (AI agent) plays independently according to the score (specialization), and the conductor (developer) adjusts the body.
The interface of AI agent interaction is also expanding. In addition to always prompting through IDE or CLI, developers can start interacting with AI agents in the following ways:
- Send a message to Slack
- Comment on Figma simulation diagram
- Create inline comments on code differences or PR
- Add feedback based on deployment-based application preview
- and using voice or call-based interfaces
- Developers can verbally describe changes
This creates a model where the AI agent runs throughout the entire life cycle of development. They not only write code, but also interpret designs, respond to feedback, and classify errors across platforms. The developer becomes the coordinator who decides which thread to pursue, discard or merge.
Perhaps most interesting is that this asynchronous pattern may change our understanding of “branches”. Traditional Git branches are forks of code. Future “branches” may be forks of intent, each branch explored in different ways by different AI agents. Instead of merging code, developers evaluate and select different solution paths.
MCP is one step closer to becoming a universal standard
MCP (Model Context Protocol) is one of the most exciting protocol innovations recently. We recently released an in-depth analysis of MCP. Since then, momentum has accelerated: OpenAI has publicly adopted MCP, several new features of the specification were merged, and tool manufacturers have begun to aggregate around it, using it as the default interface between the AI agent and the real world.
This reminds me of HTTP’s role in the 90s. HTTP is not the first network protocol, nor is it the most complex, but it is simple and good enough to be widely supported. Now MCP may be on a similar path.
At its core, MCP solves two big problems: it provides LLM with the correct context for completing tasks that may never have been seen before; it replaces N×M custom integration with a clean, modular model in which the tool exposes standard interfaces (servers) that can be used by any AI agent (client).
Here is a profound insight: we are witnessing the birth of “standardization of capabilities”. Just as USB standardizes device connections, MCP is standardizing AI agent capabilities. Any tool can expose its own features, and any AI agent can use these features without the need for customized integrations.
We expect to see wider adoption as remote MCP and de facto registry go live. Over time, the app may begin to ship with the MCP interface by default. Think about how APIs allow SaaS products to plug in and combine workflows across tools. MCP can do the same for AI agents by turning standalone tools into interoperable building blocks.
This leads to an interesting idea: the emergence of the “capacity market”. Imagine that there is a huge registry of capabilities in the future, where AI agents can discover and use new capabilities, just like developers now use npm or PyPI. Need to send an email? There is an MCP server. Need image processing? There is an MCP server. Need to customize business logic? There is an MCP server.
This is not just a technical standard, it is a new business model: Capabilities as a Service. Anyone can create an MCP server, expose a useful capability, and then let all AI agents use it. This is like the next stage of cloud computing: not only the computing resources are commodified, but the capabilities themselves are commodified.
Abstract Primitives: Every AI agent requires authentication, billing and persistent storage
This trend reflects a basic evolutionary law: the level of abstraction continues to improve. As vibe coding AI agents become more powerful, one thing becomes clear: AI agents can generate a lot of code, but they still need something solid to insert.
Just as human developers rely on Stripe for payment, Clerk for authentication, or Supabase for database capabilities, AI agents require the same clean and composable service primitives to build reliable applications. Here is an interesting observation: AI agents are not about replacing infrastructure, but about making better use of it.
In many ways, these services—the API with clear boundaries, an ergonomic SDK, and reasonable default values to reduce the chance of failure—are increasingly acting as a runtime interface for AI agents.
Think of this scenario: You tell the AI agent to “create a SaaS application with user authentication and subscription management.” What does an AI agent need? It requires a certification system (Clerk), a payment system (Stripe), a database (Supabase), and may also require mail services, file storage, etc.
This leads to a profound insight: AI agents reshape the concept of “framework”. The traditional framework gives you a structure where you fill in logic. The AI agent framework gives you a set of primitives, and AI agents can be combined into any structure.
As this model matures, we may begin to see services optimize AI agent consumption by exposing not only APIs, but also architecture, capability metadata and sample processes that help AI agents more reliably integrate them.
It’s like going from “bottom up” to “top down”. In the past, you started with infrastructure and built up layer by layer. Now, you start with your intention, and the AI agent helps you find the right building blocks. This is not reverse engineering, but forward design.
Some services may even start to ship with MCP servers by default, turning each core primitive into something that AI agents can reason and use safely and out of the box. Imagine Clerk exposes an MCP server that allows the AI agent to query available products, create new billing plans, or update customer subscriptions—all with predefined permission scopes and constraints.
The AI agent no longer requires handwritten API calls or searching in documents, it can say “create a professional version plan for Product X for $49 a month, supporting overcharges based on usage”, and Clerk’s MCP server exposes this capability, validates parameters, and handles orchestration safely.
This brings up an interesting phenomenon, which I call “declarative infrastructure”. The AI agent does not need to know how to implement user authentication. It only needs to declare “this application requires user authentication” and then let the appropriate primitive service process implement it.
The deeper impact is that this may lead to the emergence of “instant best practices”. These services not only provide functionality, but also encode best practices. When an AI agent uses Stripe integration, it automatically gains best practices for handling subscriptions, managing failed payments, processing refunds, and more.
This is like a standardized component in the construction industry. You don’t need to design an electrical system from scratch every time, you use standard switches, sockets and wiring methods. AI agents also don’t need to be certified from scratch every time, they use proven, standardized services.
The most interesting thing is the “ecosystem of capabilities” that this may create. As more and more services become AI agent friendly, we may see a new market emerge: primitive services designed specifically for AI agents. The SDKs of these services are no longer targeting human developers, but are aimed at AI agents, exposing powerful capabilities with simple interfaces and clear constraints.
Conclusion: The next chapter of software development
These nine trends point to a broader shift, with new developer behavior emerging along with stronger underlying models. In response, we see new toolchains and protocols like MCP formed. This is not just an overlay of AI on the old workflow, but a redefinition of how software is built by AI agents, contexts, and intent at the core.
I want to emphasize that these trends are not independent. They strengthen each other and together form a new developer ecosystem. AI-native version control systems rely on standardized capability interfaces; synthetic interfaces benefit from semantic accessibility APIs; asynchronous collaboration mode requires a powerful secret management system.
This reminds me of the laws of every technological revolution: at the beginning, new technologies mimic old patterns; then we begin to explore the unique possibilities of new technologies; finally, we reshape the entire system to make the most of new capabilities. We are going through the transition from phases 2 to 3.
Many developers’ tool layers are undergoing fundamental changes, which is not only a technological advancement, but also a revolution in their way of thinking. We are moving from “programming” to “intention expression”, from “version control” to “intention tracking”, from “document” to “knowledge neural networks”.
Perhaps most importantly, these trends herald fundamental changes in the role of software development. Future developers may be more like symphony conductors, coordinating the work of different AI agents than they are now, more like independent instrumentalists.
This transition is both exciting and somewhat disturbing. We are entering an unknown territory, and new rules are still forming. But history tells us that every technological revolution creates more opportunities than it destroys. The key is to maintain an open mind and adapt to changes, while adhering to the core values that make us excellent developers: solving problems, creating value, and serving users.
We are excited to build and invest in next-generation tools not only for programming more efficiently, but for solving problems that were previously unsolvable and creating possibilities that were previously unthinkable. This is what technological progress really means: not only to do faster, but to do more and do better.
Author:深思圈
Source:https://mp.weixin.qq.com/s/MGthNyHHlD4lERzDluMc1g
The copyright belongs to the author. For commercial reprints, please contact the author for authorization. For non-commercial reprints, please indicate the source.
