



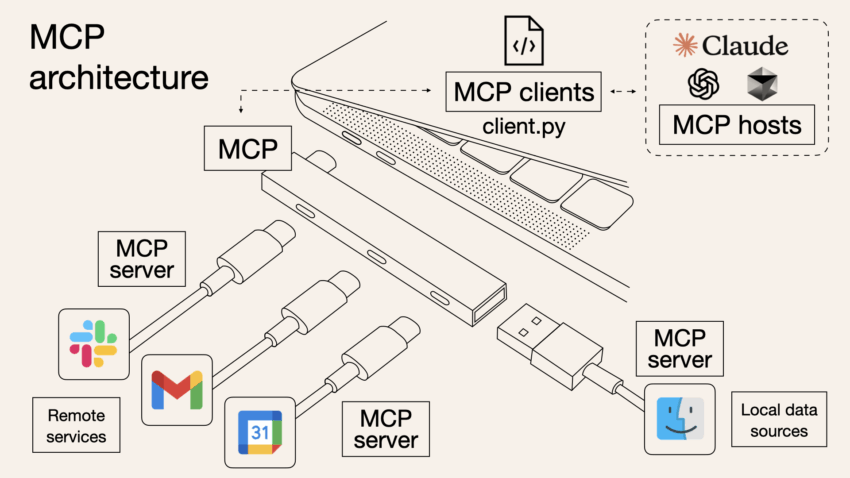
The MCP protocol released by Anthropic last year has suddenly become the hottest protocol in the AI field this year due to the craze between Manus and Agent. Major manufacturers such as OpenAI, Microsoft, and Google have also supported the agreement, and domestic Alibaba Cloud Bailian and Tencent Cloud have also quickly followed suit and launched a platform to quickly build.
But there are also many controversies. Many people question the lack of difference between MCP and API, the lack of proficiency in Internet protocols, and the security problems caused by the simple protocol, etc.
It would be more appropriate to have the inventor of the MCP protocol answer these questions.
On a recent podcast by Latent Space, they invited Justin Spahr-Summers, the inventor of the MCP protocol of the Anthropic team, to talk in detail about the origin of MCP and their many ideas about MCP: why MCP was launched, how MCP is different from existing APIs, how to make MCP better utilize tools, and so on. There is a lot of information, so it is recommended to bookmark it and read it.
Introduction to the conversation guests:
- Alessio Fanelli (Host): Decibel Partner and CTO
- swyx (host): Founder of Small AI
- David Soria Parra: Anthropic Engineer
- Justin Spahr-Summers:Anthropic Engineer
TLDR:
The “inspiration” of the MCP concept comes from an internal project of Anthropic (LSP) (Language Server Protocol). Inspired by LSP, two engineers thought about whether they could do something similar to LSP to standardize the “communication between AI applications and extensions”.
The core design principle of MCP is: the concept of tools is actually not just the tool itself, but also closely related to client applications, and is also closely connected to users. Through the operation of MCP, the user should have full control. Tools are controlled by models, which means that they are called only by the model, rather than actively specifying the use of a tool (except for prompt purposes).
Open APIs and MCPs are not opposed to each other, but are very complementary. The key is to choose the tool that best suits a particular task. MCP is more suitable if the goal is to achieve rich interactions between AI applications; open APIs are better if you want the model to easily read and interpret API specifications.
For the rapid construction of MCP servers, leveraging AI-assisted encoding is a very good way. In the early stages of development, putting the code snippets of the MCP SDK into the LLM’s context window to let the LLM help build the server. The results are often very good, and the details can be further optimized in the later stage. This is a good way to quickly implement basic functions and iterate. At the same time, Anthropic’s MCP team pays great attention to simplifying the server construction process so that LLM can participate.
The future direction of AI applications, ecosystems and Agent will tend toward Statefulness, and it is also one of the most controversial topics within Anthropic’s MCP core team. After many discussions and iterations, the conclusion was that although we are currently optimistic about the future of Statefulness, we cannot deviate from the existing paradigm, and we must find a balance between the concept of Statefulness and the complexity of practical operations.
01
How was MCP born?
swyx (host): First of all, what is MCP?
Justin: Model Context Protocol, or MCP for short, is basically a design we designed to help AI applications expand their own or integrated plug-in ecosystem. Specifically, MCP provides a set of communication protocols that allow AI applications (we call “clients”) and various external extensions (we call “MCP servers”) to collaborate with each other. The “extensions” here can be plug-ins, tools or other resources.
The purpose of MCP is to allow everyone to easily introduce external services, functions, or retrieve more data when building AI applications, so that the application has richer capabilities. Our naming contains the concept of “client-server”, which is mainly to emphasize the interaction mode, but the essence is to create a general interface that “makes AI applications easier to expand.”
However, it should be emphasized that MCP focuses on AI applications rather than the model itself, which is a common misunderstanding. Furthermore, we agree that MCP is analogized to the USB-C interface of AI applications, which is a common interface connecting the entire ecosystem.
swyx (host): The client and server features mean it is bidirectional, just like the USB-C interface, which is interesting. Many people try to do relevant research and build open source projects. I feel Anthropic is more active than other labs in winning developers. Are you curious whether this is affected by the outside world or is it that you two came up with a flash of inspiration in a certain room?
David: Actually, most of the time we thought of it in the room. This is not part of a grand strategy. In July 2024, I joined Anthropic shortly after, mainly responsible for internal developer tools. During this period, I thought about how to allow more employees to deeply integrate existing models. After all, these models are great and have better prospects. Naturally, I hope everyone can use their own models more.
At work, based on my background in developing tools, I quickly felt a little frustrated. On the one hand, because Claude Desktop has limited functions and cannot be expanded, and the IDE lacks the practical functions of Claude Desktop, it is very troublesome that I can only reply to the content between the two. Over time. I realized that this is a problem with MxN, that is, the problem of multiple applications integrating multiple applications, and solving it with one protocol is most appropriate. At that time, I was still working on an internal project related to LSP (Language Server Protocol) and there was no progress. After thinking about these ideas and thinking for a few weeks, I had the idea of building a certain protocol: Can I do something similar to LSP? Standardize this “communication between AI applications and extensions“.
So I found Justin and shared the idea, and luckily he was interested, so we set out to build it together.
Starting with the idea, it took about a month and a half to build the protocol and complete the first integration. Justin took on a lot of work in the first integration of Claude Desktop, and I did a lot of proof of concept in the IDE to demonstrate the application of the protocol in the IDE. Before the official release, you can find a lot of details by checking the relevant code base. This is the rough origin story of MCP.
Alessio (host): What is the timeline? I know November 25th is the official release date. When did you start working on this project?
Justin: I quickly excitedly set out with him to build the MCP around July after David came up with his idea. In the first few months, progress was slow because there was a lot of basic work to build a communication protocol that included clients, servers, and SDKs. But when things can communicate through protocols, it becomes exciting and can build various wonderful applications.
Later, we held a hackathon internally. Some colleagues used MCP to compile servers that could control 3D printers, and also implemented extensions such as “memory function”. These prototypes are so popular that we believe that this idea can bring great potential.
swyx (host): Back to building MCP, all we see is the final result, which is obviously inspired by LSP, and you both admit it. Want to ask how much work it takes when building? The construction process mainly involves writing a lot of code or doing a lot of design work? I feel that design work accounts for a large proportion. For example, how good is it to use JSON-RPC? What other parts are more difficult?
Justin: We get a lot of inspiration from LSP. David has a lot of experience with LSP in developing tools, I mainly work in product or infrastructure, and LSP is new to me.
From the perspective of design principles, LSP solves the M x N Problem mentioned by David. Previously, different IDEs, editors and programming languages were all in their own right, and you couldn’t use JetBrains’ excellent Java support in Vim, nor did you use Vim’s excellent C support in JetBrains. LSP allows all parties to “communicate” by creating a common language. LSP unifies the protocol, so that each “editor-language” only needs to be implemented once. Our goal is similar, except that the scenario is replaced by the docking between “AI applications-extensions”.
In terms of specific details, after adopting the concepts of JSON-RPC and two-way communication, we went in different directions. LSP focuses on functional presentation, thinking and providing different basic elements rather than semantic principles, which we also apply to MCP. After that, we spent a lot of time thinking about each fundamental element in the MCP and its reasons for its differences, which is a lot of design work. At the beginning, we wanted to support TypeScript, Python, and Rust for Zed integration, build an SDK with client and server, create an internal experimental ecosystem, and stabilize the local MCP concept (involving initiator processes, etc.).
We have referred to many criticisms against LSP and tried our best to improve them in MCP. For example, some of the practices of LSP on JSON-RPC are too complicated, so we have done some more direct implementation methods. Because when building MCP, we choose to innovate in specific fields and learn from mature models in other aspects, such as choosing JSON-RPC, but focusing on innovations such as basic elements. It is very helpful for us to learn from the achievements of our predecessors.
swyx (host): I am interested in protocol design, there is a lot of content to be expanded here. You have mentioned M x N Problem. In fact, people who work in developer tools have encountered the problem of “Universal Box”.
The basic problem and solution to infrastructure engineering is to connect many things to N different things and make a “universal box”. There are problems like Uber, GraphQL, the Temporal I worked for, and React. Are you curious about whether you solved the problem of N multiplying N on Facebook?
David: That’s true to some extent. This is a good example. I have dealt with a lot of these problems in version control systems and other aspects. It is to integrate all the problems into something that everyone can read and write, and build a “universal box” to solve them. In the field of developer tools, such problems are everywhere.
swyx (host): Interestingly, people who build “universal box” will face the same problem, namely composability, remote and local issues, etc. The functional presentation problem mentioned by Justin is that some things with the same essence need to be clarified to make it present in different ways.
02
Core concepts of MCP:
Tools, resources and tips are indispensable
swyx (host): I had this question when reading the MCP document, why do these two things have different? Many people regard tool calls as universal solutions. In fact, different types of tool calls have different meanings. Sometimes they are resources, sometimes they are execution operations, and sometimes they are other uses. I want to understand what concepts do you classify into similar categories? Why emphasize their importance?
Justin: We think about each basic concept from the perspective of application developers. When developing applications, whether it is the IDE, Claude Desktop or Agent interface, the functions you want to obtain from the integration from the user’s perspective will be much clearer. At the same time, tool calls are necessary and different functions must be distinguished.
Therefore, the initial core basic concepts of MCP were later added:
- Tool: is the core. That is, add tools to the model directly, let the model decide when to call it. For application developers, this is similar to “function calls” and is only initiated by the model.
- Resource: basically refers to data or background information that can be added to the model context and can be controlled by the application. For example: you may want the model to automatically search and find relevant resources, and then incorporate them into the context; you may also want to set up a clear user interface function in the application, allowing users to make it part of the information sent to the LLM through drop-down menus, paperclip menus, etc. These are all application scenarios for resources.
- Prompt: A text or message specially designed to be initiated by the user or replaced by the user. For example, if you are in an editor environment, it is like a slash command, or a similar automatic completion function, such as a macro that you want to insert and use directly.
Through MCP, we have our own insights into the different ways of presenting these contents, but ultimately it is up to the application developers to decide. As an application developer, it is useful to get these concepts expressed in different ways, and can determine the appropriate experience mode based on these to form differentiation. From the perspective of application developers, they do not want to make applications the same, and when connecting to an open integration ecosystem, they need unique practices to create the best experience.
I think there are two aspects: the first aspect is that tool calls currently account for more than 95% of the integration, and I expect more clients to use resource calls and prompt calls. The first implementation is the prompt function, which is very practical and can build a traceable MCP server. This is a user-driven interaction. The user determines the timing of information import, which is better than waiting for model processing. At the same time, I hope more MCP servers can use prompts to show the usage of tools.
On the other hand, the resource part is also very potential. Imagine an MCP server that discloses documents, databases and other resources, and the client builds a complete index around these. Because the resource content is rich, it is not exposed by the model, because you may have much more resource content than is actually available in the context window. We look forward to the apps being able to better utilize these basic concepts in the coming months to create a richer experience.
Alessio (host): Holding a hammer, you want to treat everything as a nail and use tool calls to solve all problems. For example, many people use it to query databases instead of resource calls. I’m curious about the advantages and disadvantages of using tools and resources when there is an API interface (such as a database)? When should I use tools to do SQL queries? When should we use resources to process data?
Justin: The way we distinguish tools from resources is: the tool is initiated by the model, and the model judges itself to find the appropriate tool and apply it. If you want LLM to run SQL queries, it is reasonable to make it a tool.
Resource usage is more flexible, but at present, the situation is very complicated because many clients do not support it. Ideally, for database table schema and other contents, they can be called through resources. Users can use this information to inform the application and start a conversation, or let the AI application automatically find resources. As long as there is a need to list entities and read them, it is reasonable to model them as resources. Resources are uniquely identified by URIs and can be regarded as general-purpose converters, such as interpreting URIs entered by users using an MCP server. Take the Zed editor as an example, which has a prompt library and an MCP server to fill the prompts interactively. Both parties need to agree on the URI and data format. This is a cool crossover example of resource applications.
Go back to the perspective of application developers, think about the needs and apply this idea to reality. For example, look at the existing application functions. If this method is adopted, which functions can be separated and implemented by the MCP server. Basically, any IDE with an attachment menu can naturally be modeled as a resource. But these implementations already exist.
swyx (host): Yes, when I saw the @ symbol in Claude Desktop, I immediately thought that this is the same as Cursor’s function, and now other users can also use this function. This design goal is great because the functionality itself is already there and people can easily understand and use it. I showed that chart, and you definitely agree with its value, I think it is very helpful and should be placed on the homepage of the document, which is a good suggestion.
Justin: Are you willing to submit a PR (Pull Request) for this? We really like this suggestion.
swyx (host): OK, I’ll submit.
As a developer relationship person, I have been committed to providing people with clear guidance, such as listing key points first and then spending two hours explaining in detail. So, it is very helpful to cover the core content with a picture. I appreciate your emphasis on Prompt. In the early days of ChatGPT and Claude, many people tried to create prompt libraries and prompt manager libraries similar to those on GitHub, but none of them really became popular in the end.
Indeed, more innovation is needed in this area. People expect the prompt to be dynamic, and you offer this possibility. I highly agree with the multi-step prompt concept you mentioned, which shows that sometimes in order to make the model run normally, you need to take multiple-step prompt methods or break through some limitations. A prompt is not just a single conversation input, sometimes it is a series of conversations.
swyx (host): I think this is where the concept of resources and tools exists in a certain way, because you now mention that sometimes a certain level of user control or application control is required, and at other times you want to be controlled by the model. So, now are we just choosing a subset of the tools?
David: Yes, I think this is a reasonable concern. Ultimately, this is a core design principle of MCP, that is, the concept of tools is actually not just the tool itself, it is closely related to client applications and is also closely connected to users. Through the operation of MCP, the user should have full control. We say that tools are controlled by models, which means that they are called only by the model, rather than actively specifying the use of a certain tool by the user (except for prompt purposes, of course, but this should not be used as a regular user interface function).
But I think it is completely reasonable for a client application or user to decide to filter and optimize the content provided by the MCP server, for example, a client application can obtain a tool description from the MCP server and display it optimized. Under the MCP paradigm, client applications should have full control. In addition, we have a preliminary idea: add functionality to the protocol, allowing server developers to logically group basic elements such as prompts, resources, and tools. These packets can be considered as different MCP servers, and then combined them by users according to their needs.
03
MCP and OpenAPI:
Competition or complementarity?
swyx (host): I want to talk about the comparison between MCP and Open API (Open API). After all, this is obviously one of the issues that everyone is very concerned about.
Justin /David: Basically, the open API specification is a very powerful tool that I often use when developing APIs and their clients. However, for the application scenarios of large language models (LLM), the open API specification seems too detailed and does not fully reflect higher-level, specific concepts for AI, such as the basic concepts of MCP and the thinking patterns of application developers we just mentioned. Compared to just providing a REST API to freely play the model, models can gain more benefits from tools, resources, tips, and other basic concepts designed specifically for it.
On the other hand, when designing the MCP protocol, we deliberately make it have a certain state. This is because AI applications and interactions are inherently more inclined toward Statefulness. Although Stateless always works to a certain extent, Statefulness will become increasingly popular as interaction modes (such as video, audio, etc.), and therefore Statefulness’s protocols are particularly useful.
In fact, open APIs and MCPs are not opposed to each other, but complement each other. They each have their own strengths and are very complementary. I think the key is to choose the tool that best suits a particular task. If the goal is to achieve rich interactions between AI applications, then MCP is more suitable; if the model is expected to easily read and interpret API specifications, then an open API would be a better choice. There were already bridges between the two in the early days, and there were tools to convert open API specifications into MCP formats for release, and vice versa, which was great.
Alessio (host): I co-hosted a hackathon at AGI Studio. As an individual agent developer, I saw someone build a personal agent that can generate an MCP server: just enter the URL of the API specification and it can generate the corresponding MCP server. How do you view this phenomenon? Does that mean that most MCP servers simply add a layer to the existing API without much unique design? Will this always be the case in the future, mainly relying on AI to connect with existing APIs, or will a brand new and unprecedented MCP experience appear?
Justin /David: I think both of these situations will exist. On the one hand, requirements like “introducing data into applications through connectors” are always valuable. Although it is currently more of a default tool call, other basic concepts in the future may be more suitable for solving such problems. Even if it is still a connector or adapter layer, it can add value by adapting different concepts.
On the other hand, there is indeed a chance to have some interesting application scenarios, building an MCP server that is more than just an adapter. For example, a memory MCP server allows LLM to remember information in different conversations; a sequential thinking MCP server can improve the model’s inference ability. These servers do not integrate with external systems, but provide a completely new way of thinking for the model.
In any case, it is completely feasible to use AI to build a server. Even if the functionality that needs to be implemented is not adapted to other APIs, but is original, the model can usually find ways to implement it. Indeed, many MCP servers will be API encapsulators, which are both reasonable and effective and can help you make a lot of progress. But we are still in the exploration stage and are constantly exploring the possibilities that can be achieved.
As clients continue to improve their support for these basic concepts, rich experiences will emerge. For example, no one has built an MCP server that can “summarize the content of the Reddit section”, but the protocol itself is fully implemented. I think when people’s demands go from “I just want to connect the things I care about to LLM” to “I want a real workflow, an experience that is really richer, I want the model to be interactive in depth”, you’ll see these innovative applications come into being. However, there is indeed a problem of “there is a chicken or an egg” between the capabilities supported by the client and the functions that server developers want to implement.
04
How to quickly build an MCP server:
Programming with AI
Alessio (host): I think there is another aspect of MCP that people discuss relatively little, that is, server construction. Do you have any advice for developers who want to start building MCP servers? As a server developer, how can we find the best balance between providing a detailed description (to let the model understand) and directly obtaining the original data (to leave it to the model for subsequent automatic processing)?
Justin /David: I have some suggestions. One advantage of MCP is that it is very easy to build some simple features and can be built in about half an hour. Although it may be imperfect, it is enough to meet basic needs. The best way to get started is: choose your favorite programming language and use it directly if there is a corresponding SDK; build a tool that you want the model to interact with; build an MCP server; add this tool to the server; simply write a description of the tool; connect it to your favorite application through the standard input and output protocol; and then observe how the model can use it.
It is very attractive for developers to quickly see the model acting on what they are concerned about, and it can inspire their enthusiasm and in turn lead them to think deeply about what tools, resources and tips are needed, and how to evaluate the results and optimize the tips. It’s a process that can be explored continuously, but starting with simple things and seeing how the model interacts with what you care about is fun in itself. MCP adds fun to development and allows models to work quickly.
I also tend to use AI-assisted coding. In the early stages of development, we found that the code snippet of the MCP SDK can be placed into the LLM’s context window, allowing LLM to help build the server. The results are often very good, and the details can be further optimized in the later stage. This is a great way to quickly implement basic functions and iterate over them. From the beginning, we have paid great attention to simplifying the server construction process so that LLM can participate. In the past few years, starting an MCP server may only require 100 to 200 lines of code, which is really simple. If there is no ready-made SDK, you can also provide relevant specifications or other SDKs to the model to help you build some of the features. It is also usually very straightforward to make tool calls in your favorite language.
Alessio (host): I found that server builders largely determine the data format and content that ends up returning. For example, in the example of tool calls, like Google Maps, which properties return are determined by the builder. If a certain property is missing, the user cannot override or modify it. This is similar to my dissatisfaction with some SDKs: when people build API encapsulated SDKs, if they miss new parameters added to the API, I can’t use these new features. How do you view this issue? How much intervention capabilities should users have, or should it be decided entirely by the server designer?
Justin /David: We may have some responsibility for the Google Maps example because it is a reference server we publish. Generally speaking, at least for the current time, for the result of tool calls, we deliberately design that it does not necessarily mean structured JSON data, nor does it necessarily need to match specific patterns, but is presented in the form of messages such as text and images that can be directly input to LLM. That is, we tend to return large amounts of data and believe that LLM can filter and extract the information it cares about. We have made a lot of effort in this regard, aiming to give the model the flexibility to get the information needed because that is exactly what it is strong. We are thinking about how to fully realize the potential of LLM rather than overly restrict or specifying, so as to avoid becoming difficult to scale as the model improves. Therefore, in the example server, the ideal state is that all result types can be passed directly from the called API, and the data is automatically passed by the API.
Alessio (host): Where to draw this boundary is indeed a difficult decision.
David: I might need to emphasize the role of AI in it here. It’s not surprising that many sample servers are written by Claude. Currently, people are often used to using traditional software engineering methods to deal with problems, but we actually need to relearn how to build systems for LLMs and trust them. With LLM making significant progress every year, it is now a wise choice to hand over the tasks of processing data to models that are good at it. This means we may need to let go of the past twenty or thirty years of traditional software engineering practice experience.
From another perspective, AI is developing at an amazing pace, exciting and a little worried. For the next wave of improvement in the model’s capabilities, the biggest bottleneck may lie in the ability to interact with the external world, such as reading external data sources and taking Statefulness actions. When working at Anthropic, we attach great importance to safe interactions and take corresponding control and calibration measures. As AI develops, people expect models to have these capabilities, and connecting models to external factors is the key to improving AI productivity. MCP is also a bet on our future direction and importance.
Alessio (host): Right, I think any API attribute with the word “formatted” should be removed. We should get the raw data from all interfaces. Why do I need to preformat? The model is definitely smart enough to format the address and other information by itself. So this part should be decided by the end user.
05
How to make MCP better call more tools?
swyx (host): I would like to ask another question, how many related functions can an MCP implementation support? This involves the question of breadth and depth, and is also directly related to the MCP nesting we just discussed.
When Claude launched its first million token context example in April 2024, it said it could support 250 tools, but in many practical situations, the model doesn’t really use so many tools effectively. In a sense, this is a breadth issue, because there is no tool calling the tool, only the model and a tile tool hierarchy, which is easy to cause tool confusion. When the functions of the tools are similar, the model may call the wrong tool, resulting in unsatisfactory results. Do you have any suggestions for the maximum number of MCP servers enabled at any given time?
Justin: To be honest, there is no absolute answer to this question. On the one hand, it depends on the model you use, and on the other hand, it depends on whether the naming and description of the tool are clear enough to allow the model to be understood accurately and avoid confusion. The ideal state is to provide all information to the LLM, which handles everything entirely, which is also the future blueprint envisioned by the MCP. But in real-life applications, client applications (i.e. AI applications) may need to do some supplementary work, such as filtering toolsets, or using a small and fast LLM to filter out the most relevant tools before passing them to large models. In addition, filtering can also be done by setting some MCP servers as proxy for other MCP servers.
At least for Claude, supporting hundreds of tools is safe. However, the situation of other models is not yet clear. Things should get better and better over time, so you need to be cautious about restrictions to avoid hindering this development. The number of tools that can be supported depends to a large extent on the degree of overlap of descriptions. If the servers have different functions, the tool name and description are clear and unique, then there may be more tools that can be supported than if there are similar functional servers (such as connecting GitLab and GitHub servers at the same time).
In addition, this is also related to the type of AI application. When building highly intelligent applications, you may reduce the configurability of your users and the interface; but when building programs like IDE or chat apps, it makes sense to allow users to choose the set of features they want at different moments instead of always enabling all features.
swyx (host): Finally, let’s focus on the Sequential Thinking MCP Server. It has branching capabilities and provides the ability to “more writing space”, which is very interesting. In addition, Anthropic released a new engineering blog last week introducing their Thinking Tool, and the community has some doubts about whether there is overlap between the sequential thinking server and this thinking tool. In fact, it’s just that different teams are doing similar things in different ways, after all, there are many ways to implement them.
Justin/David: As far as I know, the sequential thinking server has no direct common connection with Anthropic’s thinking tool. But this does reflect a common phenomenon: In order for LLM to think more thoroughly, reduce hallucinations, or achieve other goals, there are many different strategies that can present the effect more comprehensively and reliably from multiple dimensions. This is exactly what MCP is powerful – you can build different servers, or set up different products or tools in the same server to implement diverse functions, allowing LLM to apply specific thinking patterns to achieve different results.
Therefore, there is no ideal, prescribed way of thinking about LLM.
swyx (host): I think different applications will have different uses, and MCP allows you to achieve this diversity, right?
Justin/David: That’s right. I think the methods used by some MCP servers just filled the gap in the model’s own capabilities at that time. Model training, preparation and research take a lot of time to gradually improve its capabilities. Take the sequential thinking server for example. It may seem simple, but it is not, and it can be built in just a few days. However, if you want to directly implement this complex thinking function within the model, it will never be done in a few days.
For example, if the model I’m using is not very reliable, or if someone thinks the results generated by the current model are not reliable enough overall, I can imagine building an MCP server that allows the model to try to generate three results for a query, and then pick the best one out of it. With the help of MCP, this recursive and composable LLM interaction can be achieved.
06
What is the difference between complex MCP and Agent?
Alessio (host): I want to ask questions about composability next. What do you think of the concept of introducing one MCP into another? Are there any plans for this? For example, if I want to build an MCP to summarize the contents of the Reddit section, this may require calling an MCP corresponding to the Reddit API and an MCP that provides summary functions. So, how can I build such a “super MCP”?
Justin /David: This is a very interesting topic, and it can be viewed from two aspects.
On the one hand, consider building components like summary function. While it may call LLM, we want it to remain independent of the specific model. This involves the two-way communication function of MCP. Take Cursor as an example, which manages the interaction loop with LLM. Server developers can request certain tasks to the client (i.e. the application where the user is located) through Cursor, such as asking the client to summarize using the model currently selected by the user and return the results. In this way, the choice of the summary model depends on Cursor, and developers do not need to introduce additional SDKs or API keys on the server side, thus achieving a construction that is independent of the specific model.
On the other hand, it is entirely possible to build more complex systems with MCP. You can imagine an MCP server that provides support for services like Cursor or Windsurf, and the server itself acts as an MCP client to call other MCP servers to create a richer experience. This reflects a recursive feature, which also reflects this pattern in terms of specification authorization and other aspects. You can connect these applications that are both servers and clients, and even use MCP servers to build DAG (Directed Acyclic Graph) to implement complex interactive processes. Smart MCP servers can even leverage the capabilities of the entire MCP server ecosystem. People have done relevant experiments on this. If you consider automatic selection, installation and other functions, there are still many possibilities that can be realized.
At present, our SDK needs to add more details so that developers can more easily build applications that are both client and recursive MCP servers, or more conveniently reuse the behavior of multiple MCP servers. These are content that needs to be improved in the future, but they can already show some application scenarios that are currently feasible but not widely adopted.
swyx (host): This sounds very exciting, and I believe a lot of people will get a lot of ideas and inspiration from it. So, can this MCP, which is both a server and a client, be considered an Agent? To some extent, an Agent is when you make a request that will perform some underlying operations that you may not be completely clear about. There is a layer of abstraction between you and the final source of the original data. Do you have any unique insights about Agent?
Justin /David: I think it is possible to build an Agent through MCP. What needs to be distinguished here is the difference between just being an Agent’s MCP server plus a client and a real Agent. For example, inside an MCP server, you can enrich the experience with the sample loop provided by the client and let the model call the tool to build a real agent, which is relatively straightforward.
We have several different thinking directions when it comes to the relationship between MCP and Agent:
First, MCP may be a good way to express the capabilities of Agents, but perhaps there are currently some features or features that can improve the user interaction experience, which should be considered in the MCP protocol.
Second, MCP can be used as the basic communication layer that builds the agent, or allows different agents to combine with each other. Of course, there are other possibilities, such as thinking that MCP should focus more on integration at the AI application level, rather than focusing too much on the concept of Agent itself. This is still a question under discussion, and each direction has its trade-offs. Going back to the previous analogy about the “universal box”, when designing protocols and managing ecosystems, one thing we need to be particularly careful is to avoid overly complex functions and not let the protocols try to cover everything, otherwise it may cause it to perform poorly in all aspects. The key question is that to what extent the Agent can naturally fit into existing model and paradigm frameworks, or to what extent it should exist as a separate entity, is still an unfinished question.
swyx (host): I think it’s more like an Agent when implementing two-way communication, allowing the client and server to be combined into one, and delegating work to other MCP servers. I appreciate that you always keep in mind the importance of simplicity and not trying to solve all problems.07 07
MCP Next step:
How to make the agreement more reliable?
swyx (host): Recent updates from stateful servers to stateless servers have aroused everyone’s interest. You chose server sending events (SSE) as the publishing protocol and transmission method, and supported pluggable (pluggable, more flexible) transport layer. What is the reason behind this? Is it influenced by Jared Palmer’s tweets, or is it already in preparation?
Justin /David: No, we publicly discussed Statefulness’s difficult problems with Stateless on GitHub a few months ago and have been weighing them all the time. We believe that the future development direction of AI applications, ecosystems and Agent tends to be Statefulness. This is one of the most controversial topics within the MCP core team, which has been discussed and iterated many times. The final conclusion is that although we are optimistic about the future of Statefulness, we cannot deviate from the existing paradigm as a result. We must find a balance between the concept of Statefulness and the complexity of practical operations. Because if the MCP server is required to maintain long-term continuous connection, it will be very difficult to deploy and operate. The basic idea of the original SSE transport design was that after you deploy an MCP server, the client could connect in and keep it connected nearly indefinitely, which is a high requirement for anyone who needs to operate at a large scale, not an ideal deployment or operational model.
Therefore, we think about how to balance the importance of Statefulness with ease of operation and maintenance. Our streamable HTTP transmission methods, including SSE, are designed step by step. The server can be a normal HTTP server that gets the results through HTTP POST requests. Then you can gradually enhance features, such as supporting streaming results, and even allowing the server to proactively make requests to the client. As long as the server and client support Session Resumption (session recovery, which means you can reconnect and continue to transmit after disconnection), you can achieve convenient expansion while taking into account Statefulness interactions and better cope with network instability and other conditions.
Alessio (host): Yes, the session ID is also included. Do you have any plans for future identity verification? Currently, for some MCPs, I just need to paste my API key in the command line. What do you think is the future development direction? Will there be something like MCP-specific configuration files to manage authentication information?
Justin /David: In the next draft revision of the agreement, we have included the authorization specification. Currently, the main focus is on user-to-server authorization, using OAuth 2.1 or its modern subset. This method has a good effect and everyone is building it based on this. This can solve many problems, because you definitely don’t want users to paste API keys at will, especially considering that most servers will be remote servers in the future, and secure authorization is required between them.
In a local environment, since the authorization information is defined in the transport layer, this means that data frame encapsulation (setting the request header), and the standard input and output (stdin/stdout) cannot be directly implemented. However, when running programs using standard input and output locally, the operation is very flexible and you can even open a browser to handle the authorization process. We are not fully determined internally as to whether to use HTTP for authorization locally. Justin tends to support it, and I personally do not agree with it and there is controversy.
Regarding authorized design, I think like other contents of the agreement, we strive to be quite streamlined and solve actual pain points. The functions are simplified first, and then gradually expand according to actual needs and pain points to avoid over-design. Design protocols need to be very cautious because once a mistake is made, it is basically irreversible, otherwise it will undermine backward compatibility. Therefore, we only accept or add those that have been well considered and verified, and let the community make temporary attempts through the extension mechanism first until there is a broader consensus that certain features should indeed be added to the core protocol and that we have the ability to continue to support in the future, which will be easier and more robust.
Taking authorization and API keys as examples, we have done a lot of brainstorming. The current authorization method (OAuth 2.1 subset) can meet the usage scenarios of API keys. An MCP server can act as an OAuth authorization server and add related features, but if you access its “/authorize” web page, it may simply provide a text box for you to enter the API key. While this may not be the ideal way, because it does fit the existing model and is feasible in the moment. We are worried that if too many other options are added, both the client and the server need to consider and implement more situations, which will increase complexity.
Alessio (host): Have you ever considered the concept of scopes? Yesterday we made a show with Agent.ai’s founder Dharmesh Shah. He gave an example of email: he had all his emails, hoping to have more fine-grained Scopes controls, such as “you can only access these types of emails” or “only access the emails sent to this person.” Today, most scopes are usually designed based on the REST API, i.e. which specific endpoints you can access. Do you think it is possible for future models to understand and utilize the Scopes layer to dynamically limit transmitted data?
Justin /David: We recognize the potential demand for Scopes and have also been discussed, but adding it to the protocol requires great caution. Our standard is to first find practical problems that cannot be solved by the current implementation, and then prototype the MCP structure based on the scalability and prove that it can bring a good user experience before it is considered formally incorporated into the protocol. The situation of authorization is different, it is designed more from the top-down.
Every time we hear a description of Scopes, we find it very reasonable, but we need specific end-to-end user cases to clarify the shortcomings of the current implementation method so that we can further discuss. Considering the design philosophy of composability and logical grouping, we usually recommend that the MCP server be designed to be relatively small, with a large number of different functions being best implemented by independent, discrete servers and then combined at the application layer. Some people also raised objections, disagreeing with allowing a single server to undertake the authorization task of multiple different services, believing that these services themselves should correspond to their own independent servers, and then combine them at the application level.
08
Security issues with MCP server distribution
Alessio (host): I think one of the excellent designs of MCP is its programming language irrelevance. As far as I understand, Anthropic does not have an official Ruby SDK, nor does OpenAI. Although developers like Alex Rudall have performed well in building these toolkits, with MCP, we no longer need to adapt the SDK separately for various programming languages, just create a standard interface that is recognized by Anthropic, which is great.
swyx (host): Regarding the MCP Registry, five or six different registration centers have appeared, and the official initial announcement of the registration center has ceased operations. The service model of the registration center, such as providing downloads, likes, evaluations and trust mechanisms, is easily reminiscent of traditional software package repositories (such as npm or PyPI), but this makes me feel unreliable. Because even with social proof, the next update may put an originally trusted software package at a security threat. This kind of abuse of trust systems feels like building a trust system and being damaged by the trust system itself. Therefore, I prefer to encourage people to use MCP Inspector because it only requires looking at the traffic of communications, and many security issues may be discovered and solved in this way. How do you view the security issues and supply chain risks of registration centers?
Justin /David: Yes, you are completely correct. This is indeed a typical supply chain security issue that all registries can face. There are different solutions to this problem in the industry. For example, you can adopt a model similar to Apple’s App Store to strictly review the software, form an automated system and a manual review team to complete this work. This is indeed a solution to this type of problem and is feasible in certain specific scenarios. But I think this pattern may not be very applicable in an open source ecosystem, because open source ecosystems usually adopt decentralized or community-driven methods like MCP registry, npm package manager, and PyPI (Python package index).
swyx (host): These warehouses are essentially facing the problem of supply chain attacks. Some core servers that have been released in the official code base are currently available, especially those with special servers such as memory servers and reasoning/thinking servers. They seem to be more than simply encapsulating existing APIs, but may be easier to use than just manipulating APIs.
Take the memory server as an example. Although there are some startups on the market that focus on memory functions, using this MCP memory server, the code volume is only about 200 lines, which is very simple. Of course, if more complex extensions are needed, more mature solutions may be required. But if you just want to quickly introduce memory functionality, it provides a very good implementation and may not need to rely on products from those companies. Do you have any special stories to share with these non-API encapsulated special servers?
Justin /David: Actually, there are not many special stories. Many of these servers are derived from the hackathon we mentioned earlier. At that time, people were very interested in the idea of MCP. Some engineers within Anthropic who wanted to implement memory functions or try related concepts could use MCP to quickly build prototypes that were difficult to implement in the past. You no longer need to be an end-to-end expert in a certain field, nor need specific resources or private code bases to add features such as memory to your application or service. This is how many servers were born. At the same time, we are also considering how wide a range of functional possibilities to be displayed when publishing.
swyx (host): I completely agree. I think this has made your release a success to some extent, providing a wealth of examples for people to copy and paste directly and expand on this basis. I also want to focus on the file system MCP server, which provides the function of editing files. I remember Eric showed off his excellent bench project before in the podcast, and the community was very interested in the open source file editing tools. There are some related libraries and solutions on the market that regard this file editing capability as the core intellectual property, and you directly open source this function, which is really cool.
Justin /David: File system server is one of my personal favorite features. It solved a practical limitation I encountered at the time. I had an amateur game project and was very eager to associate it with cloud services and the “artifacts” mentioned earlier by David. It is of great significance to be able to interact with cloud services and local machines, and I like this feature very much.
This is a typical example. This server was born from the setbacks we encountered in creating MCP and the need for such functionality. Justin is particularly impressed by this from encountering problems to developing MCP and this server. Therefore, it occupies a special place in our hearts and can be regarded as a spiritual origin of this agreement.
09
MCP is now a large-scale project involving many companies
swyx (host): The discussion about MCP is very lively. If people want to participate in these debates and discussions, what channels should they go through? Is it directly on the standard codebase discussion page?
Justin /David: It is relatively easy to express your opinions on the Internet, but it takes effort to put them into practice. Jason and I are both supporters of traditional open source concepts, and we believe that actual contributions are crucial in open source projects. If you demonstrate your results with concrete examples through practical work, and put your energy into the extensions you want in the Software Development Kit (SDK), then your ideas are more likely to be adopted by the project. If you just stay at the level of expressing your opinions, your voice may be ignored. We certainly value all kinds of discussions, but given the limited time and energy, we prioritize those who have put more actual work into it.
The number of discussions and notifications related to MCP is huge, and we need to find more scalable architectures to interact with the community to ensure that the discussion is valuable and productive. Running a successful open source project sometimes requires making some difficult decisions that may not satisfy some people. As a maintainer and manager of a project, it is necessary to clarify the actual vision of the project and firmly advance in the established direction. It doesn’t matter if someone disagrees, because there may always be projects that are more suitable for their philosophy.
Taking MCP as an example, it is just one of many solutions to solve problems related to the general field. If you do not agree with the direction chosen by the core maintainers, the advantage of open source is that you have more choices, and you can choose the “fork” project. We do expect community feedback and strive to make the feedback mechanism more scalable, but at the same time we also make the choices we think are the right ones. This may cause a lot of controversy in open source discussions, but it is sometimes the essence of such open source projects, especially in the field of rapid development.
swyx (host): Fortunately, you don’t seem strange to making difficult decisions. Facebook’s open source project provides a lot of experience to learn from, and even without direct participation, you can understand the participants’ practices. I was deeply involved in React’s ecosystem and had previously formed a working group and the discussion process was open. Every member of the working group has a say and is someone with real work and important contributions, and this model has been helpful for a while. Regarding GraphQL, its development trajectory and early popularity are somewhat similar to that of current MCP. I went through the development of GraphQL, and eventually Facebook donated it to the Open Source Foundation.
This begs the question: Should MCP do the same? This question is not simply “yes” or “no”, there are trade-offs. Most people are currently satisfied with Anthropic’s work on MCP, after all, you created and managed it. But when the project develops to a certain scale, you may encounter bottlenecks and realize that it is a company-led project. One would eventually expect true open standards to be driven by nonprofits, with multi-stakeholder and good governance processes, such as those managed by the Linux Foundation or the Apache Foundation. I know it may be too early to discuss this issue, but want to hear what you think about it?
Justin /David: Governance in the open source field is indeed an interesting and complex issue. On the one hand, we are committed to building MCP into an open standard, open agreement and open project that welcomes all interested parties to participate. It is currently going well, for example, many of the ideas for streaming HTTP come from different companies such as Shopify, and this kind of cross-company cooperation is very effective. But we do worry that official standardization, especially through traditional standardization agencies or related processes, may significantly slow down the development of projects in areas like AI. Therefore, we need to find a balance point: how to solve possible concerns or problems in governance models while keeping existing parties active participation and contributions, and find the right future direction without experiencing repeated organizational changes.
We sincerely hope that MCP is a truly open project. Although it was initiated by Anthropic, and David and I both work at Anthropic, we don’t want it to be regarded as just “Anthropic’s protocol”. We hope that all AI labs and companies can participate or take advantage of it. This is very challenging and requires efforts to balance the interests of all parties and avoid falling into the dilemma of “the committee’s decisions lead to the stagnation of projects.” There are many successful management models in the open source field, and I think most of the subtleties revolve around the sponsorship of enterprises and the right to speak in the decision-making process. We will deal with these related issues properly and we absolutely hope that MCP will eventually become a real community project.
In fact, many non-Anthropic employees currently have permission to submit and manage MCP codes. For example, the Pydantic team has submission permissions to the Python SDK; companies such as Block have made many contributions to the specifications; SDKs in Java, C#, Kotlin and other languages are completed by different companies such as Microsoft, JetBrains, and Spring AI, and these teams have complete management permissions. So, if you look closely, it is actually a large-scale project with multiple companies involved, and many people are contributing to it, not just the two of us have submission rights and related rights on the project.
Alessio (host): Do you have any special “wish list” for future MCP servers or clients? Are there any features you particularly want people to build but not yet implemented?
Justin /David: I would like to see more Support for Sampling clients. I also hope someone can build some specific servers, such as servers that can summarize Reddit’s discussion of thread content, or get servers that were dynamic last week on EVE Online. I especially hope that the former (sampling client) will have nothing to do with the model – not that I don’t want to use other models besides Claude (because Claude is the best at the moment), but rather that I purely hope to have a support for Sampling client framework.
More broadly, it would be even better if there were more clients that supported the full MCP specification. We designed the possibility of gradual adoption in mind, which would be great if these well-designed basic concepts could be widely used. Recalling my motivation for my initial involvement in MCP work and my excitement about file system servers—
I’m a game developer in my spare time, so I really want to see an MCP client or server integrated with the Godot engine (I was developing games with the Godot engine at the time). This makes it very easy to integrate AI into the game, or to allow Claude to run and test my game. Let Claude play the Pokémon game, for example. Now there is a foundation to realize this idea. Going further, how about letting Claude use Blender to build 3D models for you?
swyx (host): Frankly speaking, even things like shader code can be implemented theoretically. This is indeed beyond my professional field. But when you give developers support and tools, what they can do is really amazing. We are preparing for a “Claude” hackathon with David Hersh. I didn’t have a plan to incorporate MCP into it, but now it seems that I might consider it.
Author:Founder Park
Source:https://mp.weixin.qq.com/s/atAFAacpH2_-vh3GH3br5w
The copyright belongs to the author. For commercial reprints, please contact the author for authorization. For non-commercial reprints, please indicate the source.
