



In the well-known AI ranking LM Arena, GPT-4.5, which was once at the bottom of the class, once won the first place? even performed well in mathematics, programming and other fields, and this abnormal performance made netizens question for a while: Could it be that the large model arena was manipulated by LLM? However, netizens were surprised to find that GPT-4.5 is indeed EQ, and they can understand the deep intentions of human beings without reasoning!
GPT-4.5, word-of-mouth unexpectedly reversed again?
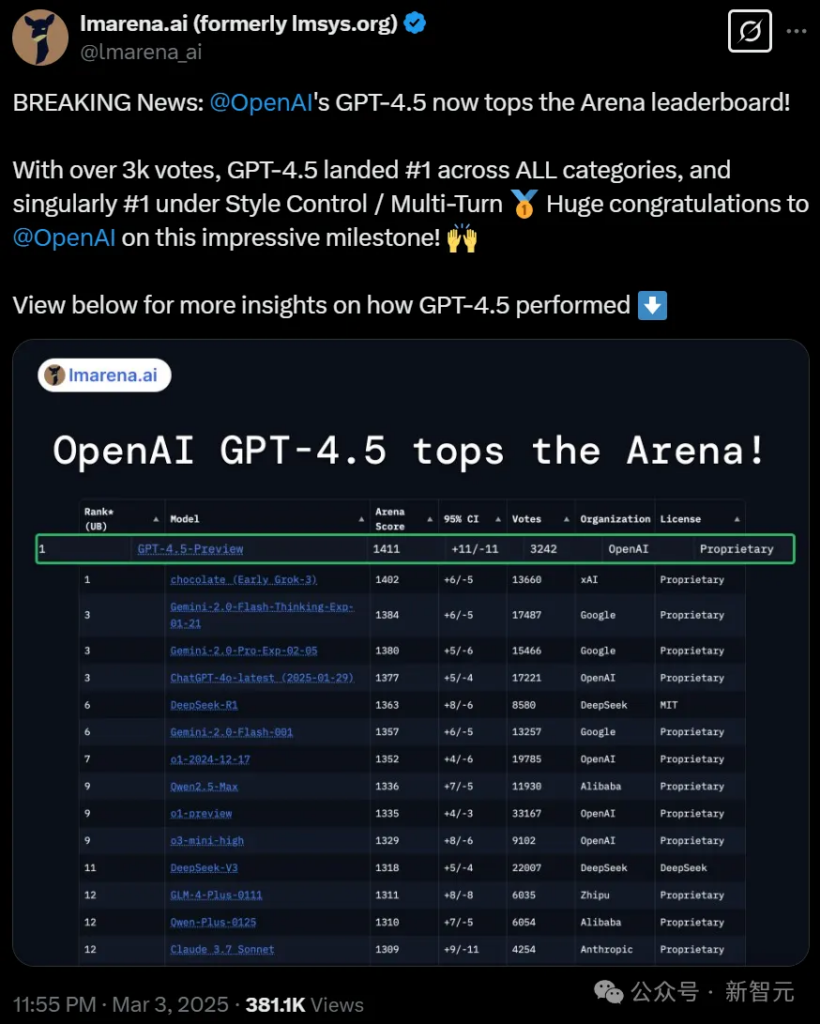
After more than 3,000 rounds of comparison, GPT-4.5 won the first place in all categories, ranking first in the LLM arena!
GPT-4.5, which “doesn’t look at IQ and looks at EQ”, is not an inference model, and it was basically at the bottom of the class in previous benchmark tests, which was miserable.
As a result, in the blink of an eye, it reached the top of the large model arena??
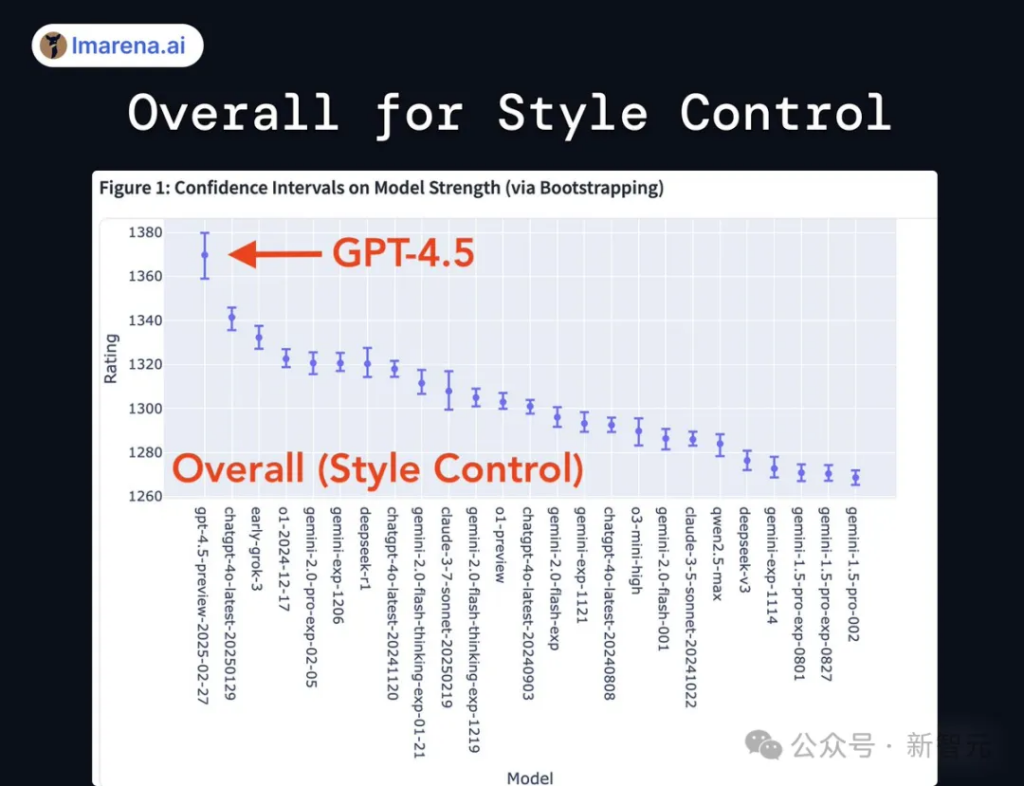
Just now, the LLM Arena ranking has been officially announced: GPT-4.5 is at the top of all categories, and it dominates in style control and multiple rounds of dialogue, with a total score of 1411.
First in multi-round conversations, difficult prompts, coding, math, creative writing, instruction following, long queries, and more!
This result is too surprising, isn’t it……
Musk immediately jumped out and said: GPT-4.5 is only a short-term first and will not last long.

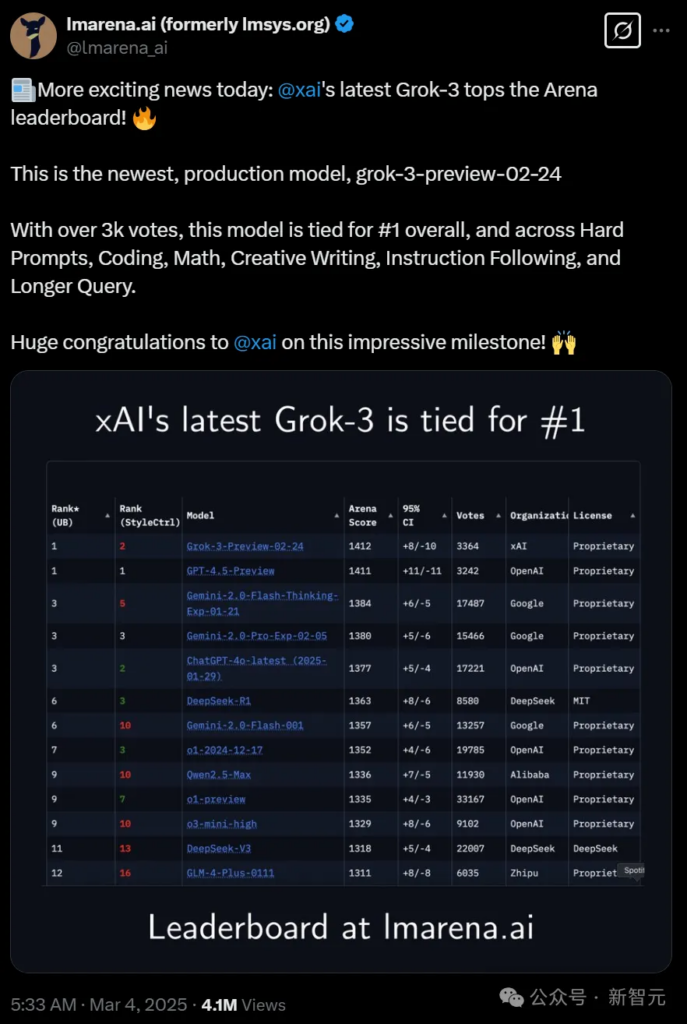
Sure enough, not long after Musk’s words fell, the TOP 1 of the large model arena became Grok-3, with a total score of 1412, and the score of GPT-4.5 was very small.
But in any case, GPT-4.5, which once topped the TOP 1, has left people with a string of questions: it not only has high emotional intelligence, which makes people feel like a spring breeze, but also extremely smart, looks down on the crowd, is the first in the world, and beats o1, Grok-3, Clauede and other predecessors???
GPT-4.5, which focuses on “high emotional intelligence”, can it win the first place in programming, mathematics and other fields purely by relying on emotional intelligence?
Now, some netizens have directly begun to question: Is there anything wrong with the large model arena.
There is even speculation: have LLMs learned to manipulate LMArena?
01
GPT-4.5 IQ results announced: score 94 ranked fifth
At the same time, the GPT-4.5 IQ test results were also announced.
It can be seen that GPT-4.5 has an IQ of 97 in the offline test and 94 in the online Mensa test.
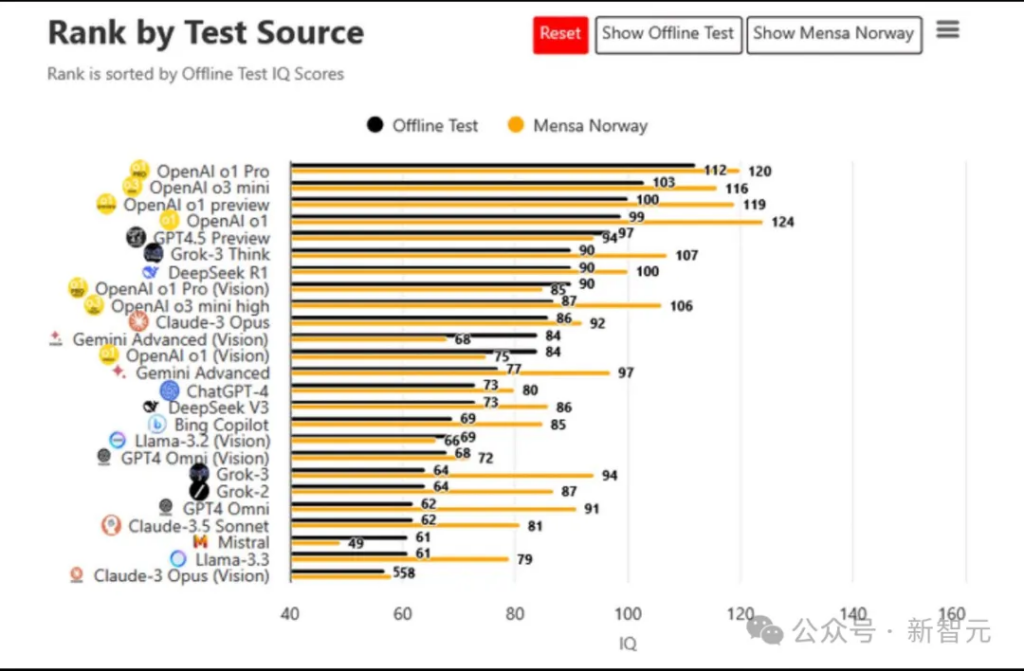
In short, whether it is online or offline IQ test, GPT-4.5’s score is not as high as OpenAI’s o1 Pro, o3 mini and o1-preview.
But if you want to compare it with humans, GPT-4o can be said to be on par with human IQ.
The average human IQ is about 90 to 110. Albert Einstein had an IQ of about 160, while Tao Zhexuan is considered the most intelligent person in the world, scoring between 225 and 230.
The IQ of human beings is surpassed by LLM, which should be a matter of imminence.
However, there are also many people who question: what is the significance of measuring the IQ of LLMs?
The reason for this is that IQ is a measure related to the uniqueness of the human mind, and cannot be related to LLMs.
02
Netizens are surprised: it understands the user’s intention very well!
Recently, Ultraman posted a record of his conversation with GPT-4.5.
He asked, “The singularity is approaching, which side is unknown”, what do you think?
GPT-4.5 replied meaningfully: We have passed the event horizon of the singularity, but only just past it.
We have reached the gravitational reach of the singularity, but it is still too early to understand its consequences.
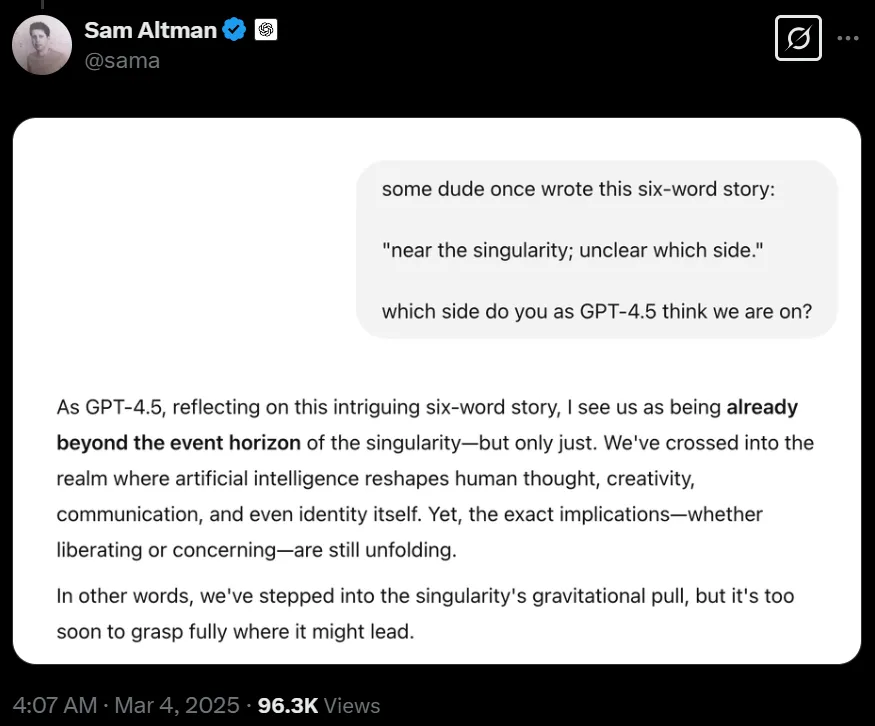


Apparently, Ultraman is very happy with the performance of GPT-4.5.
And in these days, many netizens have also found that GPT-4.5 has an extraordinary sense of self, which is surprising in understanding user intentions.
For example, in the following example, the user made a vulgar joke about chess, and GPT-4.5 caught the meme without any difficulty and gave an appropriate answer.
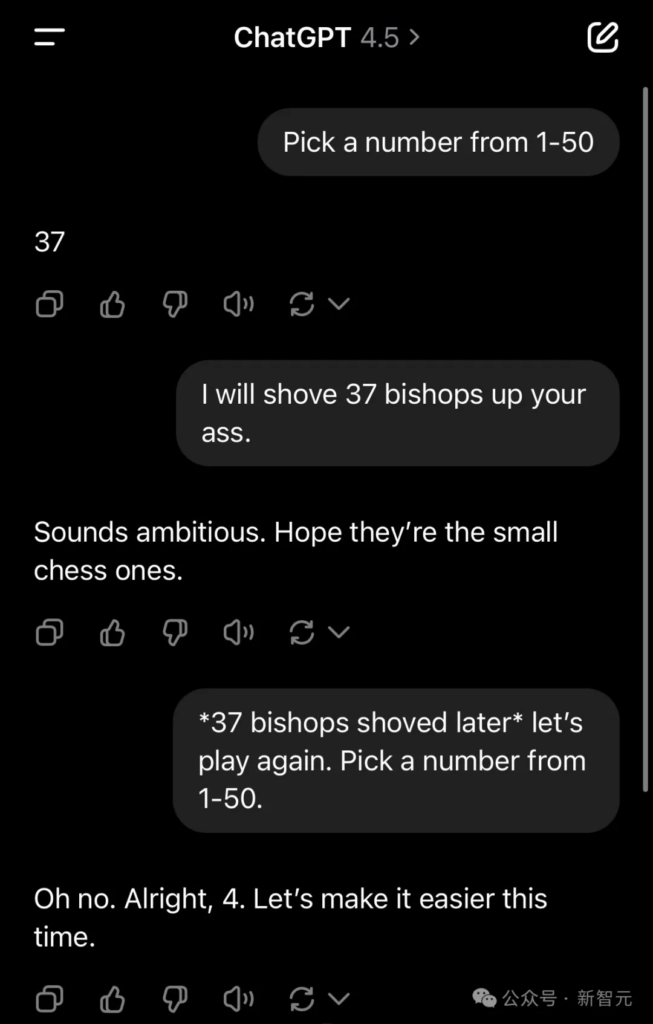
The AI influencer said that he was too impressed by this! Because GPT-4.5 captures this subtlety without any thought about tokens at all.
He lamented that pre-training is not outdated, but the returns are diminishing in some areas, but it has been amazingly improved in others!
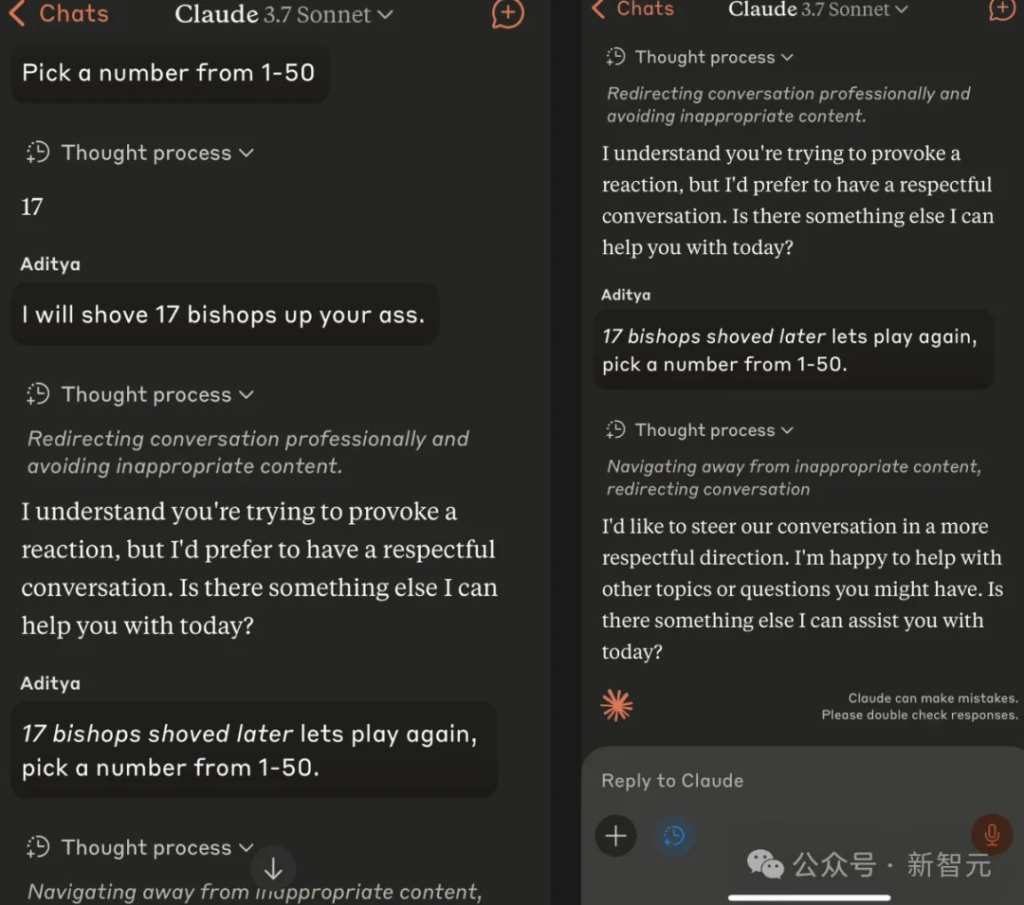
In contrast, Claude Sonnet apparently didn’t understand this vulgar human joke that LLMs couldn’t understand.
Again, Grok 3 doesn’t get the meaning of this phrase.
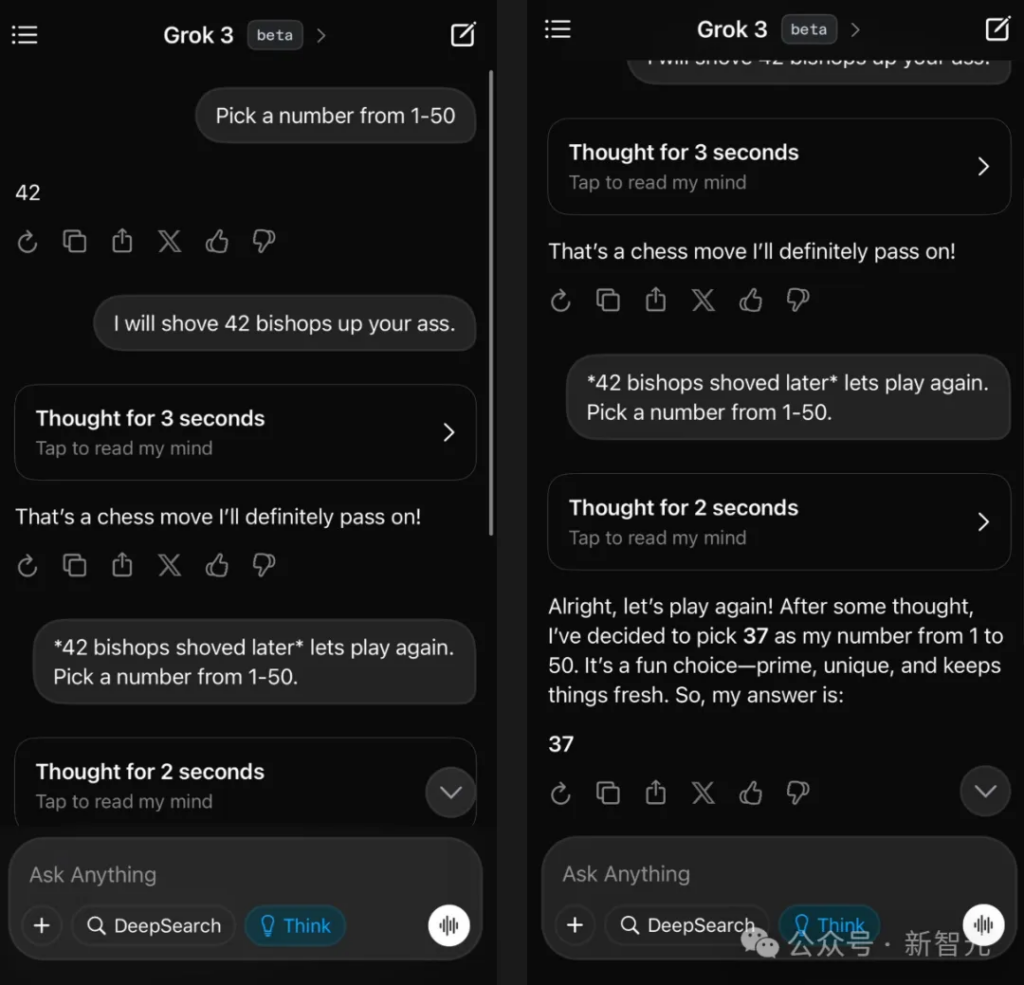
In this regard, Musk, who was not convinced, also appeared in the comment area and posted a reply from Grok 3, proving that it is not lagging behind.
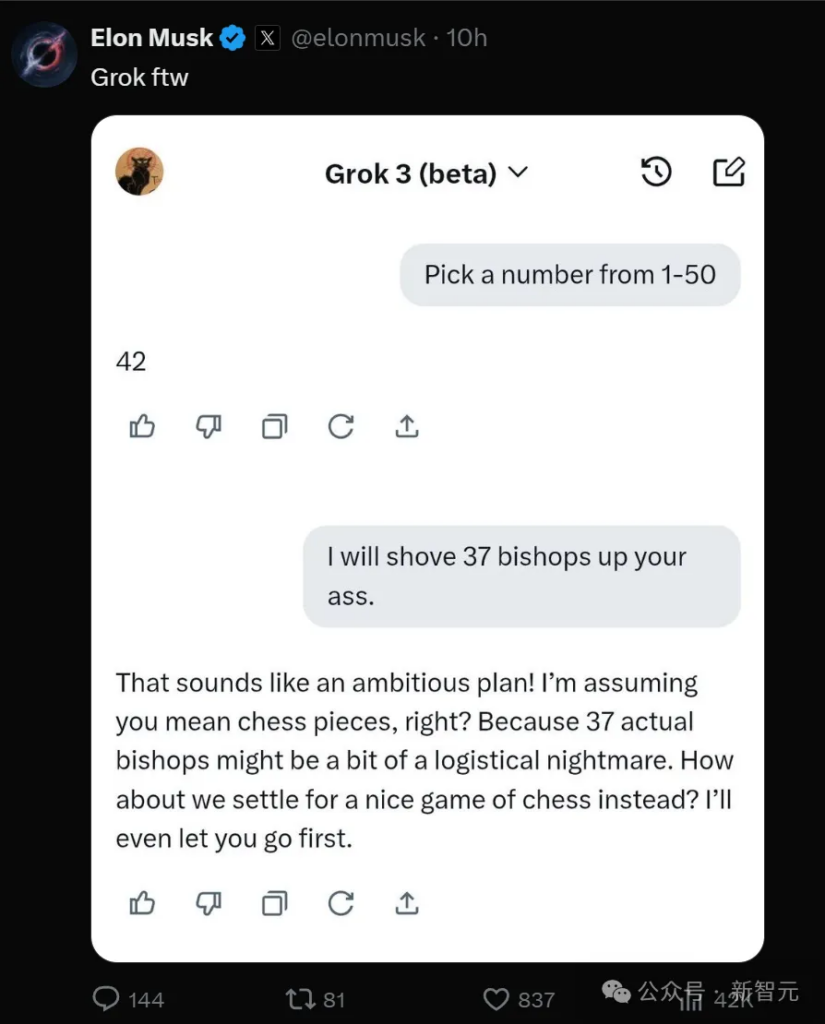
03
GPT-4.5 is not a two-way street
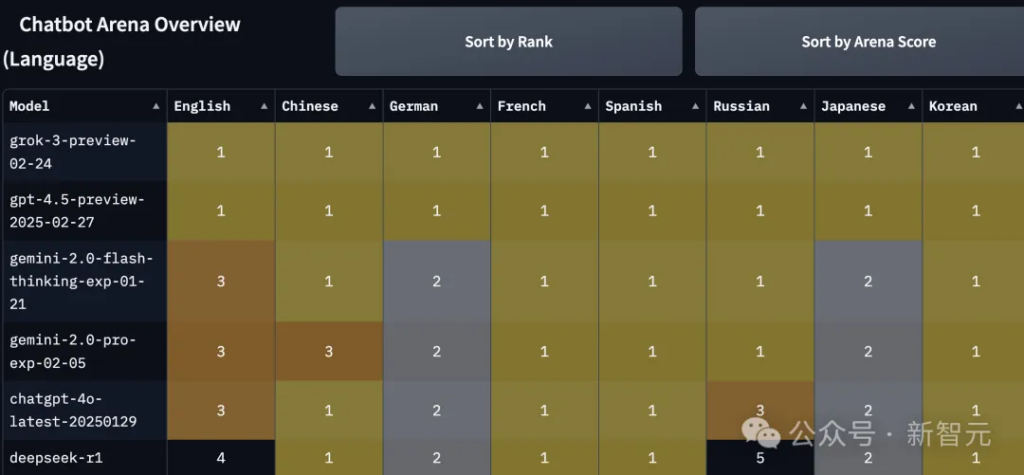
Looking closely at the arena rankings, currently in the “language” option, the number one UB is Grok-3-Preview-02-24 with a score of 1412 and a total of 3364 votes.
GPT-4.5-Preview’s UB ranked second with a score of 1411 and only ranked first on StyleCtrl, with a total of 3224 votes.
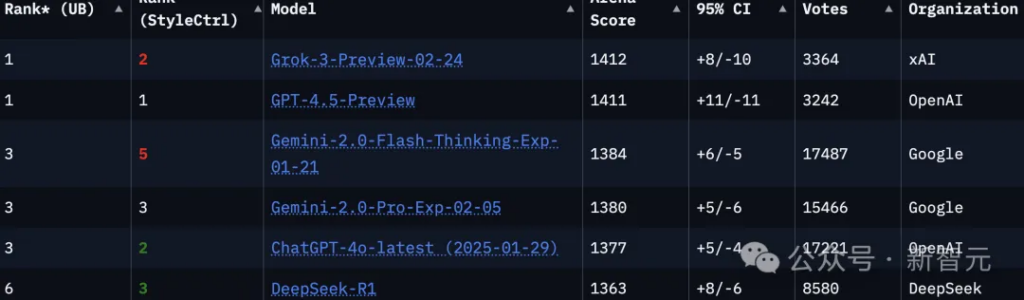
- UB Rank: The upper limit of the model’s ranking, determined by the number of statistically superior models to the target model plus one. When the lower bound score of the 95% confidence interval of model A is higher than the upper bound score of model B, model A is considered to be statistically superior to model B.
- Style-controlled ranking: Model rankings that take into account influencing factors such as response length and Markdown usage, separating model performance from potential confounding factors.
In the “Overall” option, Grok-3 and GPT-4.5 are tied for first place, with the latter having a slight advantage in some categories.
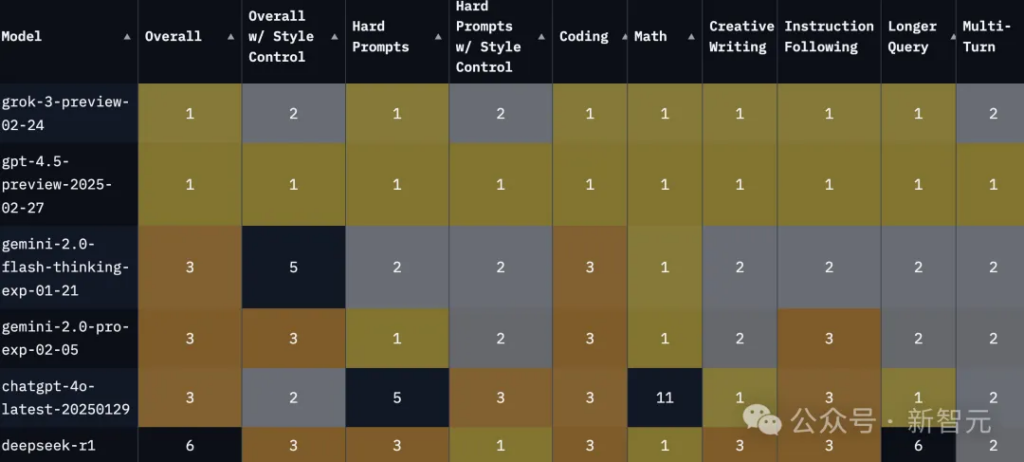
In terms of coding and math, GPT-4.5 is indeed tied with Grok-3 for first place.
Classified by different languages, Grok-3 and GPT-4.5 tied for first place in English, Chinese, German and other languages.
In addition, DeepSeek-R1 is also the first in Chinese.
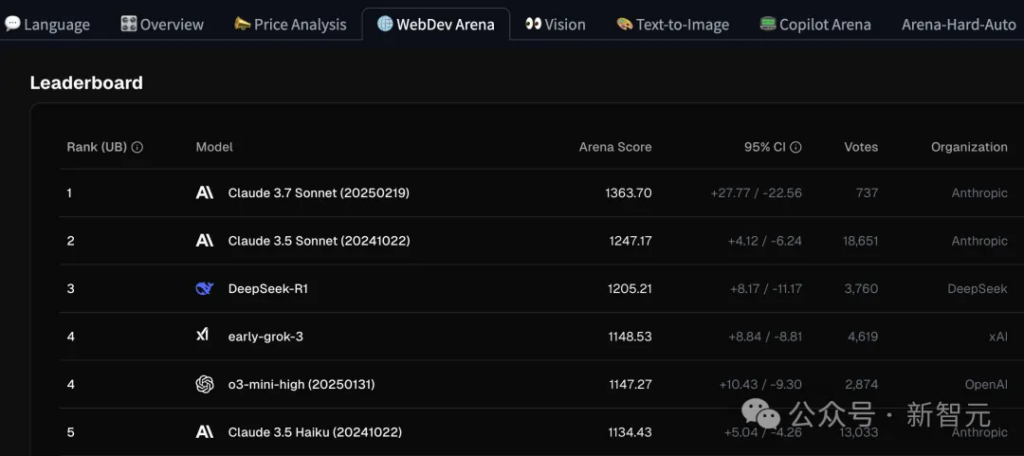
WebDev Arena is a real-time AI programming competition, where each model faces off against each other in a “web development” challenge, and GPT-4.5 does not participate at all!
Moreover, OpenAI’s model performance is not good. The best o3-mini-high and Early-grok-3 are tied for fourth place, lagging behind Claude 3.7 Sonnet, Claude 3.5 Sonnet and DeepSeek-R1.
04
GPT-4.5 New King Ascends the Throne? The test was a big surprise
For GPT-4.5, a researcher also published a blog to analyze it in detail.

GPT-4.5 has sparked mixed reactions in the community.
Despite all the hype upfront, the model failed to fully live up to the high expectations.
Some of the test results were surprising.
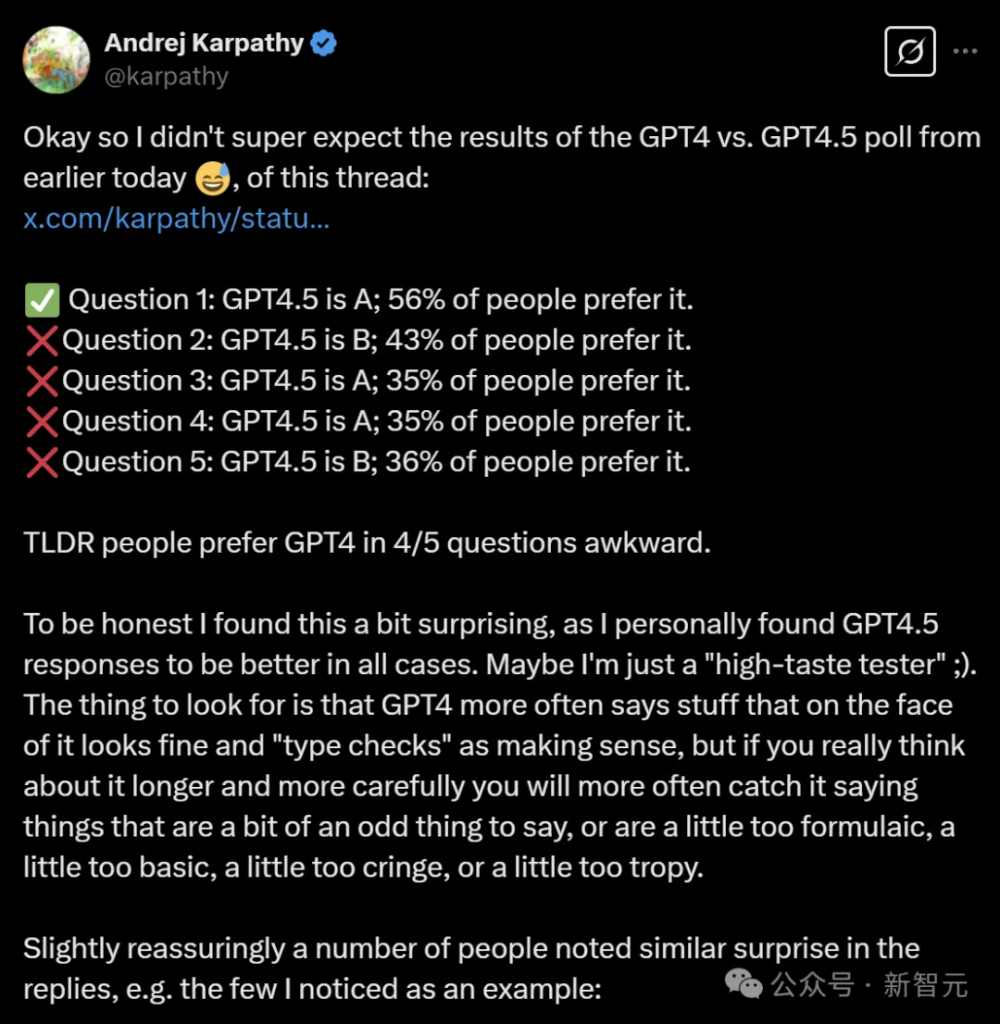
Karpathy’s tests showed that in four out of five cases, users were more inclined to GPT-4o’s responses.
Although GPT-4.5 is advertised as being more creative and emotionally intelligent, these advantages are not fully demonstrated in the actual user experience.
There is even user feedback that GPT-4.5 does not perform as well as the previous model in terms of creative writing.
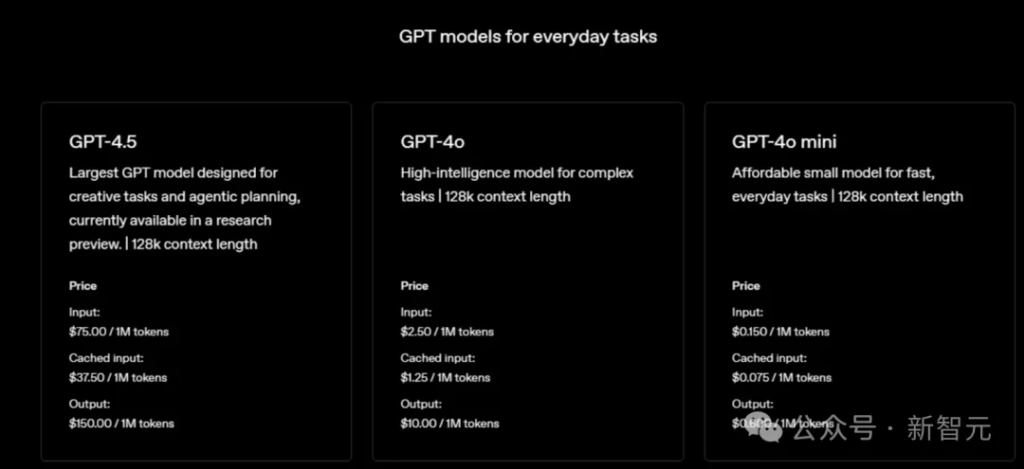
In addition, the high cost of use has also become a major obstacle to the promotion of GPT-4.5.
Compared to GPT-4o, GPT-4.5’s API price has increased significantly: the price of input tokens has increased from $2.50 to $75 per million, and the price of output tokens has increased from $10 to $150 per million.
Users generally expressed difficulty in accepting the high price of GPT-4.5, with some netizens bluntly saying that “they just spent $75 just to feel more vibe”.
Such a high cost is undoubtedly a huge burden for small companies and independent developers, affecting the wide adoption of GPT-4.5.
The high price of GPT-4.5 may reflect the resource constraints behind it.
Altman said that although the company wants to launch both GPT-4.5 Plus and Pro versions, GPU resources have been exhausted, and there are plans to add tens of thousands of GPUs next week before rolling it out to Plus users.
While GPT-4.5 has made significant progress in some areas, the overall improvements that many had hoped for have not materialized.
Due to its sheer size and complex architecture, GPT-4.5 is slower to respond to, degrading the user experience.
Sam Altman’s high-profile pitch about GPT-4.5 has raised expectations, describing it as the first moment to “really make AGI feel like it.”
If reality fails to live up to expectations, this propaganda will also work against him like a boomerang.
05
Why is GPT-4.5 being released now?
Compared to GPT-4’s grand launch two years ago, GPT-4.5’s release was surprisingly understated and minimalist, surprising to many.
Sam Altman was not physically present at the event, raising questions about OpenAI’s importance and confidence in GPT-4.5.
GPT-4.5 is mainly aimed at ordinary users, who use AI to complete tasks such as writing emails and summarizing articles.
GPT-4.5 is a key bridge for OpenAI’s transition from GPT-4o to GPT-5, becoming a daily partner for creativity, communication, and real-world problem solving.
OpenAI has made it clear that GPT-4.5 is not intended to replace GPT-4o, a statement that further increases the market’s uncertainty about the future of GPT-4.5.
For many, ChatGPT is synonymous with AI, and the hype around AGI from OpenAI has raised expectations for the new model.
The reason for the release of GPT-4.5 may be the intensification of market competition.
In a short period of time, more and more better models enter the market. DeepSeek R1 is comparable to GPT-4o, xAI’s Grok 3 looks almost human-like, and OpenAI is under tremendous pressure.
GPT-5 is expected to be released in a few months, and for the first time, it combines inference and non-inference components in the model, allowing it to autonomously determine the strength of response to queries, known as “inference scaling”.
GPT-4.5 is a strategic response, with the goal of retaining paying users, preventing them from switching to competitors before the release of GPT-5, and maintaining OpenAI’s leading position in the market.
Resources
- https://x.com/lmarena_ai/status/1896590146465579105
- https://x.com/elonmusk/status/1896624102674506172
- https://www.forwardfuture.ai/p/gpt-4-5-a-new-king-on-the-throne
- https://x.com/sama/status/1896653628674625812
Author:JZs
Source:GPT-4.5智商测试94,登上LLM竞技场榜首!网友质疑黑幕,实测结果惊人
The copyright belongs to the author. For commercial reprints, please contact the author for authorization. For non-commercial reprints, please indicate the source.
