



NVIDIA has consolidated its position in the AI market with its CUDA ecosystem and hardware advantages.
1) DeepSeek claims to train models at one-tenth the cost of GPT-4, which has caused concerns about the collapse of computing power demand. However, “underwater demands” such as multimodal models and real-time reasoning have gradually emerged, and the acceleration of model iteration has instead pushed up the market’s long-term demand for computing power.
2) In addition to the explosive data given in previous financial reports, Nvidia’s real moat is hidden in the ecological barrier built by 280 million lines of CUDA code. Its software stack advantages have formed industry standards, and the migration cost is extremely high. Even if the hardware performance of competitors is close, the software ecological gap is still difficult to bridge.
3) Current data proves that despite the significance of DeepSeek’s breakthrough, no tech giant has cut capital expenditures on computing and data centers. The upcoming 2024Q4 financial report may boost investor sentiment again. Nvidia’s 2025 revenue is expected to remain extremely optimistic, and the GTC conference on March 17 (focusing on physical AI projects such as GB300, Rubin, and robots) will also reveal new highlights.
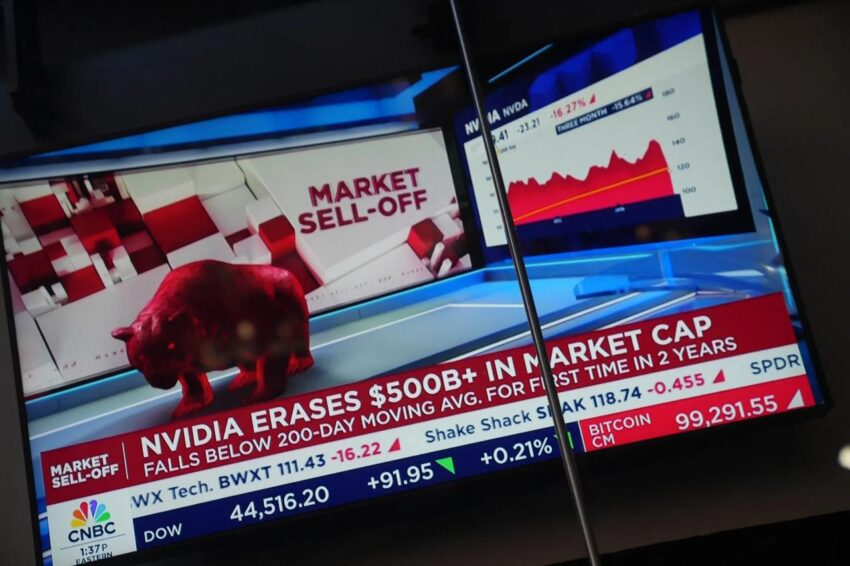
On January 27, 2025, the U.S. stock market witnessed a historic moment: Nvidia plummeted 17% in a single day, and its market value evaporated by US$590 billion, setting a record for the largest single-day market value loss in the history of the U.S. stock market.
The epicenter of this earthquake came from a Chinese AI company, DeepSeek. It claimed to have trained a model with equivalent performance at one-tenth the cost of GPT-4, instantly tearing apart the market’s consensus on the demand for AI computing power.
But what is even more dramatic is that in less than a month, Nvidia’s stock price has basically recovered all its losses. The bulls who remained optimistic and chose to buy at the bottom have bought at a low point again.
The RockFlow investment research team believes that the roller coaster market of Nvidia reflects the market’s overreaction to short-term sentiment, and the subsequent rebound verifies the irreplaceable nature of its core competitiveness and industry position. Last August, we analyzed the real moat of Nvidia, which the market has not paid enough attention to, and why we believe that Nvidia is not only a great company, but also an investment target with a high potential return rate in the article “Why Nvidia broke through 4 trillion”.
This article will provide an in-depth review of why the $590 billion flash crash was misjudged, as well as our long-term reasons and short-term catalysts for being optimistic about Nvidia.
The essence of market panic: misjudgment of technology path and demand structure
The release of the DeepSeek R1 model was like a “bomb” thrown into the computing power market: it was trained with only 2,000 H800 GPUs at a cost of $6 million. In comparison, GPT-4 cost as much as $100 million, and Llama 3 used 16,000 H100s. This order of magnitude cost difference instantly caused the market to fall into panic over the “computing power demand collapse theory.”
Some investors mistakenly believed that improved model efficiency would directly reduce reliance on Nvidia’s GPUs, causing short-term pressure on its stock price.

But there is a misjudgment point here – the illusion of cost accounting. In fact, the $6 million only covers the cost of GPU rental and electricity, while the real training cost also includes many hidden expenses such as data cleaning, algorithm engineer salaries, and experimental losses. Research organization Semianalysis pointed out that if the full cost is included, DeepSeek’s actual expenditure may reach $30 million.
More importantly, market panickers ignore the “iceberg structure” of AI computing power demand: the current model training demand is only the visible part, which may only account for 10%, while the underwater part includes the exponential growth of computing power consumption of multimodal models (video/3D generation), the rigid requirements of real-time reasoning (such as Tesla’s autonomous driving) for low-latency hardware, and the repeated training requirements brought about by the accelerated model iteration speed.
The real disruptiveness of DeepSeek this time is that its open source strategy (free and open R1 model) directly challenges OpenAI’s subscription system (20-200 US dollars/month), causing turbulence in the AIaaS valuation system. In addition, it may also lead to the diversion of the long-tail market, especially small and medium-sized developers may turn to cost-effective solutions such as Trainium 2, but Nvidia’s core customers (hyperscale data centers) are difficult to migrate due to the CUDA ecosystem binding.
In general, there are two core logics behind the market’s short-term panic misjudgment:
First, although model optimization (such as sparse computing and algorithm improvement) reduces training costs, the faster iteration of large models (such as multimodal and real-time learning) will increase the total demand for long-term computing power.
Second, they underestimated the resilience of Nvidia’s demand structure: its core customers are concentrated in cloud vendors (AWS, Azure) and leading AI companies (OpenAI, Meta), and its capital expenditure plans focus on “infrastructure expansion” rather than simply pursuing single-task costs.
Nvidia’s rebound driving force: fundamentals and ecological barriers
When the market is boiling over DeepSeek, don’t forget the reality revealed by Nvidia’s 2024Q3 financial report: Hopper architecture chips (H200) are conquering data centers at the fastest speed in history. The core highlights of last quarter’s financial report include but are not limited to:
Data center revenue: $30.8 billion (up 112% year-on-year), of which cloud service providers (CSPs) contributed more than 50%
Blackwell demand: The first batch of samples triggered a buying spree, and Huang Renxun said “demand exceeded the most optimistic expectations”
Profit margin game: Although Blackwell’s gross profit margin dropped to 75% in the early stage of mass production, it will recover to the mid-75% as production capacity increases.

Hopper’s strong sales in the third quarter helped the data center division’s revenue grow 112% year-over-year to $30.8 billion. CFO Colette Kress said on the earnings call:
H200 sales have grown to billions of dollars consecutively, the fastest growing product in the company’s history. H200 has 2x better inference performance and 50% better TCO. Cloud service providers account for about half of data center sales, with revenue growing more than 2x year-over-year.
NVIDIA H200-based cloud instances are now available from AWS, CoreWeave, and Microsoft Azure, with Google Cloud and OCI (Oracle Cloud Infrastructure) coming soon. In addition to significant growth from large CSPs, NVIDIA GPU regional cloud revenue grew 2x year-over-year as North America, EMEA, and Asia Pacific ramped up NVIDIA cloud instance and sovereign cloud buildouts.
Outside of CSPs, Nvidia more than doubled its revenue from consumer internet companies, which bought Hopper chips to support training of next-generation AI models, multimodal and agent AI, deep learning recommendation engines, generative AI, and content creation.
Kress said in the earnings call that the company has delivered the first Blackwell samples to customers in the third quarter. Blackwell is its latest architecture series and is in high demand due to its powerful performance. Two or three years ago, it took weeks or even months to train large AI models on hardware, but Blackwell can greatly reduce this time. In the fast-moving AI industry, the faster developers can bring innovative products to market, the greater the chance of success.
Management forecasts fourth-quarter total revenue of $37.5 billion. If this forecast is met, fourth-quarter revenue will increase 69.7% year-over-year, and full-year 2024 revenue will increase 111% from 2023 to $128.66 billion.
In addition to the explosive data given in previous financial reports, Nvidia’s real moat is hidden in the ecological barriers built by 280 million lines of CUDA code. Its software stack advantages: CUDA and AI libraries (such as TensorRT) have formed industry standards, and the migration cost is extremely high. Even if the hardware performance of competitors (such as AMD) is close, the software ecological gap is still difficult to bridge.
In addition, NVIDIA’s system-level solutions (DGX SuperPOD, OVX server and other full-stack solutions) are deeply bound to customer infrastructure, and replacement requires the reconstruction of the entire technology stack. This ecological control is further strengthened in the Blackwell era: its NVLink 5.0 technology achieves ultra-high-speed chip interconnection bandwidth, which is several times that of AMD MI300X. When the hardware performance gap exceeds a certain critical point, the cost-effectiveness loses its meaning.
Nvidia started out as a hardware company that produced GPUs. However, it is evolving into a company that provides end-to-end AI solutions. It is providing customers with software tools to build chatbots, AI virtual assistants, and virtual agents. It is not just a chip provider, but a full-fledged AI giant.

It also emphasizes the total cost of ownership (TCO) of its entire AI infrastructure solution, rather than just focusing on manufacturing chips, making it more difficult for rivals that only sell cost-effective chips to compete. Nvidia incorporates the entire hardware and software ecosystem, support, operating expenses, and the ability to quickly deploy AI solutions into its TCO calculations, and management hopes to be able to say to customers: “Our AI chips may cost more upfront, but in the long run, the entire AI solution can save costs.”
Therefore, although DeepSeek and the momentum of reducing AI costs pose a certain threat to Nvidia, Nvidia does not need to worry too much.
The “arms dealer” logic of the AI competition remains unchanged
The current theme among the tech giants is that business growth is still limited by their ability to build data centers and provide computing power. None of them have cut capital spending on computing and data centers. And their growth in cloud computing remains strong.
In the past 12 months, the top three CSPs have invested $186 billion to expand their computing power. In the new year, Meta expects capital expenditures to be between $60 billion and $65 billion, Microsoft expects to invest about $80 billion to expand data centers, Amazon has set a tone of at least $100 billion, and Alphabet expects capital expenditures to reach $75 billion.
At the same time, the recently launched “Stargate” project claims to cost $500 billion and aims to promote the development of AI in the United States. Oracle alone has identified 100 data centers for future development in this project. In the field of physical AI, Tesla completed the assembly of 50,000 H100 clusters at the Texas Super Factory in 2024, which will be used for autonomous driving. Musk said that the computing power needed to develop the Optimus humanoid robot needs to be increased by 10 times.
Vishwanath Tirupattur, head of research at Morgan Stanley, believes that although DeepSeek’s breakthrough is significant, it will not lead to a collapse in capital expenditures by related giants with a significant impact in AI and related fields.
He mentioned that the sharp decline in computing costs in the 1990s provides a useful reference for this. At that time, the investment boom was driven by two factors: one was the speed at which companies replaced depreciating capital, and the other was the continued sharp decline in the price of computing capital relative to the price of output. If the efficiency gains brought by DeepSeek reflect similar phenomena, then AI capital costs may fall and help support corporate spending prospects.
The continued increase in spending by technology giants has undoubtedly provided strong support for computing companies such as Nvidia. Amazon CEO Andy Jassy pointed out in a conference call that most companies’ AI computing relies on Nvidia’s chips, and Amazon will continue to maintain a cooperative relationship with Nvidia in the foreseeable future.
Not to mention, last year Huang Renxun repeatedly stated that countries around the world are planning to build and operate their own AI infrastructure domestically, which will drive demand for Nvidia products.
In an interview with Bloomberg, he stressed that countries such as India, Japan, France and Canada are discussing the importance of investing in “sovereign AI capabilities.” “Their natural resource – data – should be refined and produced for their countries. The recognition of sovereign AI capabilities is global.”
Of course, it must be acknowledged that as American technology giants are determined to invest huge amounts of money in the field of AI, the uncertainties faced by Nvidia are gradually increasing: for example, the biggest winners in recent times are the two major AI ASIC giants – Broadcom and Marvell Technology.
With their technological leadership in inter-chip interconnection and high-speed data transmission between chips, Broadcom and Marvell Technology have become the core force in the AI ASIC market. Technology giants such as Microsoft, Amazon, Google, and Meta are working with Broadcom or Marvell Technology to develop their own AI ASIC chips for the deployment of massive AI computing power at the inference end.
In addition, according to Reuters, OpenAI is advancing plans to reduce its dependence on Nvidia and open a new chapter for its chip supply by developing its first generation of internal artificial intelligence chips. Sources said it will complete the design of the first internal chip in the next few months and plans to send it to TSMC for manufacturing. The latest news shows that OpenAI is expected to achieve its mass production goal in 2026.
However, these factors do not hinder Nvidia’s “arms dealer” logic in the AI competition, and Nvidia believers call the sell-off caused by DeepSeek a bargain hunting opportunity. They still believe in three supporting factors:
1) The market’s confidence in Hopper and Blackwell chips is growing;
2) While investor sentiment toward large training clusters is under pressure, there are signs that large clusters are still being built;
3) The inference market is expected to drive NVIDIA’s growth for many years, and NVIDIA’s position in the inference field is solid.
In the short term, the upcoming 2024Q4 financial report may boost investor sentiment again. Nvidia is expected to reconfirm the execution of Blackwell; data center revenue in 2025 will increase by more than 60% year-on-year; and Nvidia will build momentum in advance for the GTC conference on March 17 (focusing on physical AI projects such as GB300, Rubin, and robots).
In conclusion
The RockFlow investment research team believes that the DeepSeek impact incident will eventually go down in the history of technology, not because it changed the rules of the game, but because it verified the unshakable nature of the rules: in the infinite war of AI, computing power is not an option, but a necessity; it is not a cost item, but an asset item.
As the “infrastructure provider” of the global AI arms race, Nvidia’s irreplaceability will continue to strengthen during the industry expansion cycle. Although ASIC and self-developed chips pose long-term disturbances, Nvidia will still be the biggest winner in the AI computing power expansion cycle in the next 3-5 years.
When the market cheered for the “efficiency revolution”, NVIDIA took a month to prove that the real moat is never in the gross profit margin figures in the financial statements, but in the “import torch.cuda” command typed by every developer, in the DGX SuperPOD roaring in every data center, and in mankind’s eternal desire to expand the boundaries of intelligence.
Author:RockFlow
Source:https://mp.weixin.qq.com/s/bQFm_4ioJq-YgT1C2Iq9Cg
The copyright belongs to the author. For commercial reprints, please contact the author for authorization. For non-commercial reprints, please indicate the source.
