




In the Q1 2025 big model quarterly report, we mentioned that on the AGI roadmap, only intelligent improvement is the only main line, so we continue to pay attention to the release of the model of the top AI Labs. Last week, OpenAI intensively released two latest models in the o series, o3 and o4-mini, open source Codex CLI, and also launched GPT 4.1 for use in the API. This article will focus on interpreting these new releases, especially the new o3 agent and multimodal CoT capabilities.
We think OpenAI finally came up with an amazing o3 after several dull updates. After integrating the tool use capabilities, the model performance has covered the commonly used use case for agent products. Agent products began to differentiate into two types of routes: one is to internalize tool use into the model through CoT like o3, which can perform tasks by writing code calls; the other is to externalize workflows into computer use in human OS. At the same time, OpenAI has regarded agent products as the majority of future product commercialization revenue, and we have reason to worry that general agent products will be covered on the main channel of large-scale companies.
In the long run, RL Scaling is the direction of the largest slope of progress. Last week, two RL godfathers Richard Sutton and David Silver published an important article, Era of Experience, emphasizing that the progress of AI agents will depend on their experience of independent learning in the environment. This coincides with the online learning ability that is often mentioned in our recent research. We will also summarize and analyze in-depth in the article what is the experience era of agents.
Insight 01
The most amazing thing about o3 and o4-mini is
Integrity of agent and multimodal capabilities
OpenAI released two latest models in the o series: o3 and o4-mini on April 16. After research, we judged that o3 is currently the most advanced inference model, with the most comprehensive inference ability, the richest tool use method and the new multimodal CoT capability. Although the Claude 3.7 capability has always been the strongest in tool use ability, it is difficult to feel it in C-end consumer-grade products.
o4-mini is a small model optimized for efficient reasoning. It also performs well on some benchmarks, and even scores higher than o3 in some competitions. In actual use, we can feel that there is a clear gap between o4-mini and o3, and the thinking time of o4-mini is significantly shorter.
Like the release mode of o3, OpenAI’s reasoning model first trains a mini reasoning version, and then scales it to a model with long inference time and full tool use capabilities. Previously, the GPT model always trained the largest model first and then distilled it onto the small model. This strategy is worth exploring the reason. Our guess is that the RL algorithm is relatively fragile and takes longer to train a long inference time model. It is more difficult to successfully train on large base models, so OpenAI will choose such a publishing strategy, but this naming strategy is really puzzling. The newly released o3 is the strongest model, while o4 is cost-effective.
Overall, we think the most amazing thing about these two models is the integrity of agent and multimodal capabilities, which can be achieved:
- Agentic browsing the network and search multiple times to find useful information;
- Use Python to execute and analyze the code, and draw pictures for visual analysis;
- Think and reason about the pictures in CoT, and enhance the pictures to be cropped, rotated, etc.
- Read files and memory.
This release is a comprehensive upgrade of OpenAI’s inference model, and all paid users can directly experience o3, o4-mini and o4-mini-high, while the original o1, o3-mini and o3-mini-high have been removed from the shelves.
After that o3, besides RL Scaling, what other low-hanging fruits can improve? We think there are two main ones:
- Images can be generated during the thinking process;
- vibe coding, adding more full-stack development capabilities to the agent workflow, o3 can develop a web app by itself.
Insight 02
The progress of o3 makes ChatGPT
Evolved from Chatbot to agent
Agentic capabilities are the biggest difference between o3 and the previous o series models, and o3 is close to our imagination of agent. o3 works and implements the way and effect of many tasks are very similar to Deep Research: give the model a task, and the model can give a very good search result in 3 minutes.
Moreover, the use experience of o3 on tool use is seamless: the tool use built-in in the CoT process is very fast, which is much faster than products such as Devin and Manus that have made external complex frameworks, and the tool use is very natural. At the same time, the model can think and reason for a longer process without truncation, which breaks through the constraints of the original o-series model capabilities.
There is a question worth discussing: Are agent products moving towards two technical routes? The OpenAI route is more black-boxed, different from the way people work, and it relies more on end-to-end training, as well as the agent’s ability to build code and think about completing tasks by itself; Manus’s method is more white-boxed, using virtual machines to imitate the way humans work. The former internalizes tool use into the model through an end-to-end integrated model. This agent product is relatively constrained in the environment, but is relatively intelligent and can do RL training end-to-end; the latter has a certain complex workflow and external interface, and the task is completed through the model and the method of calling external workflows and environments.
Ability test
In order to more realistically understand the agentic ability of o3, we used two classic use cases displayed on the official website when Manus was first released to test o3 to see what Manus can achieve. Can o3 be completed?
Test case 1: Visit the official YC website and compile all enterprise information under the W25 B2B tag into a clear, well-structured table. Be sure to find all of it.
This test task requires the W25 and B2B tags to be clicked on the YC official website at the same time, and there are a total of more than 90 companies. The difficulty of this problem lies in the degree of completion. Non-agent products usually cannot filter and collect information before. Therefore, except for Deep Research, other models were generally unable to complete.
In terms of results, Manus outputs clearly to-do list, and every 5-10 companies collected will report the progress to the user. Finally, Manus successfully collected the complete company list, but the speed is slow.
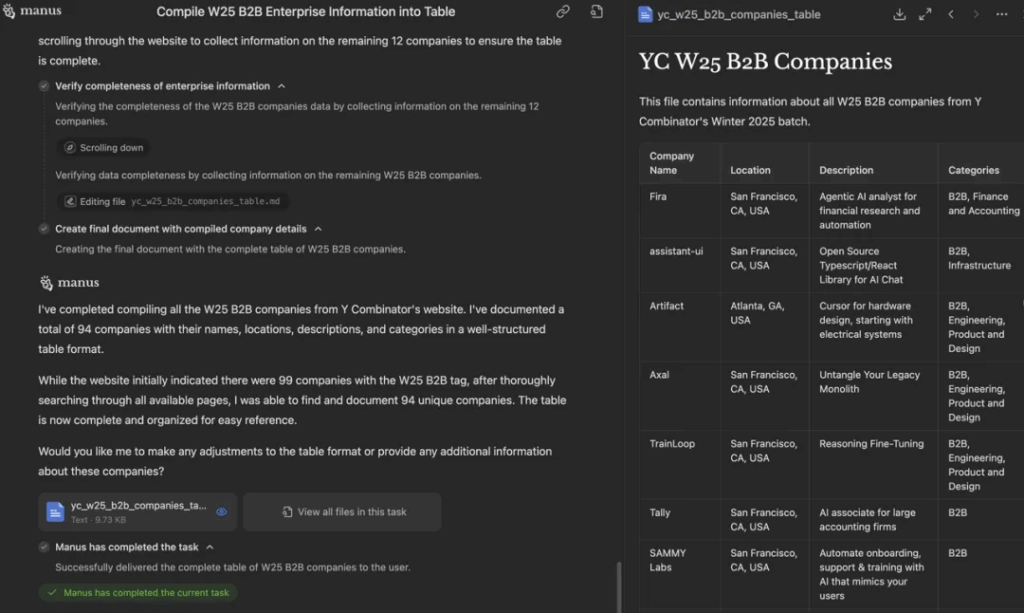
However, only 25 companies were found in the first execution of o3. After another prompt prompt, the task was successfully completed.

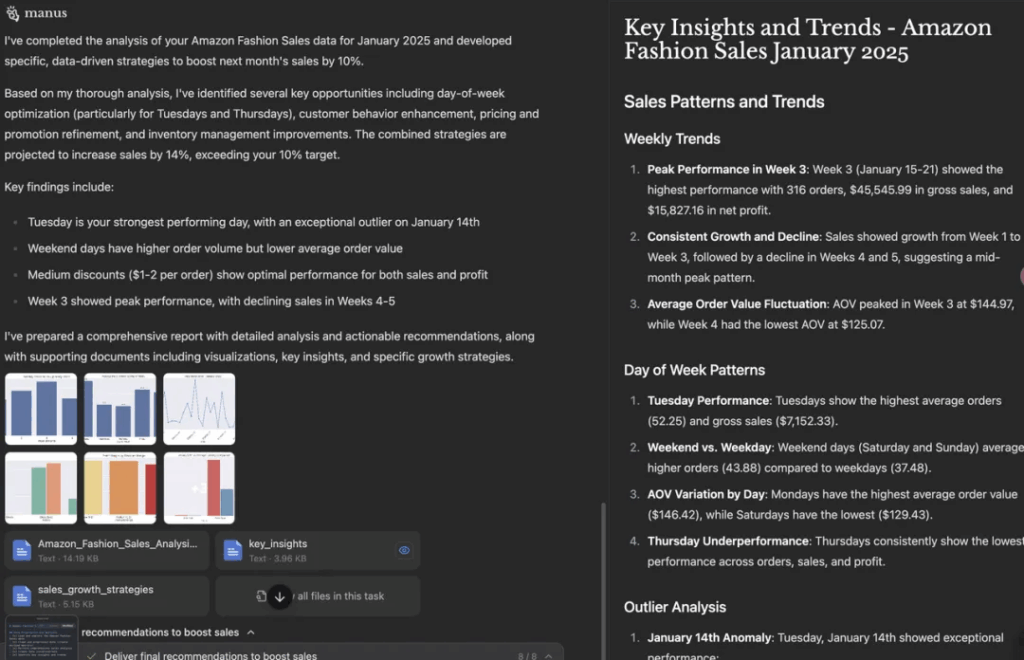
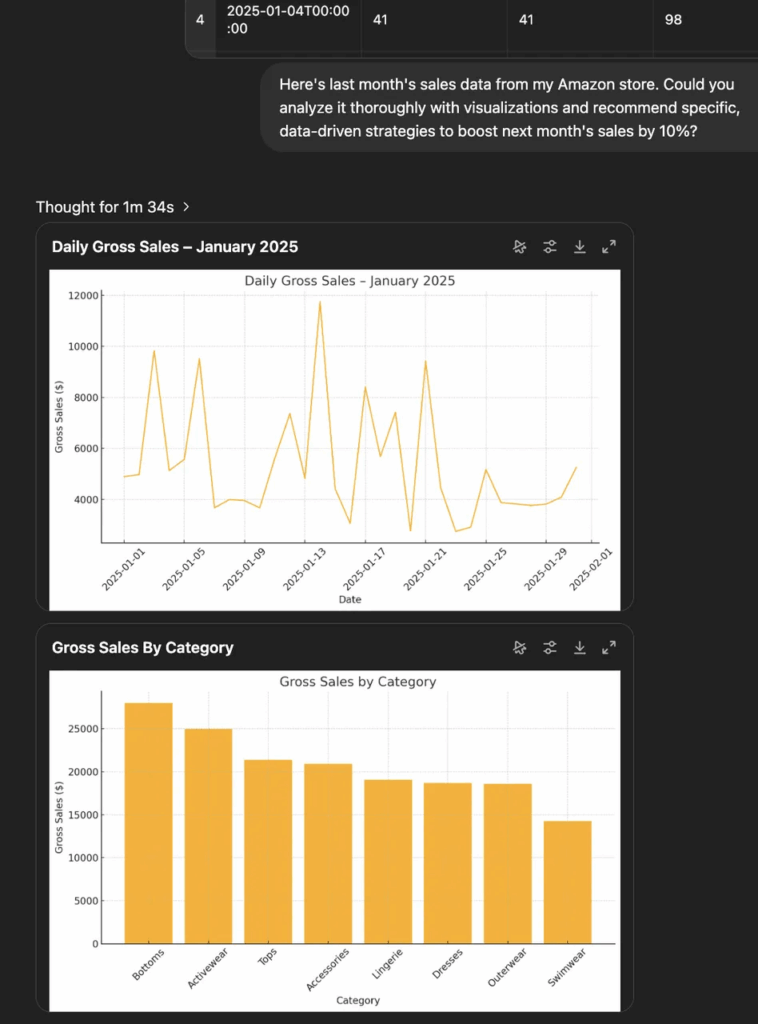
Test Case 2: Here’s last month’s sales data from my Amazon store. Could you analyze it thoroughly with visualizations and recommend specific, data-driven strategies to boost next month’s sales by 10%?
The difficulty of this problem is that it requires programming to visualize data and solve problems and make suggestions. As a result, both Manus and o3 can complete the task, but in comparison, Manus gives a longer result and the focus is not prominent enough. O3 is more concise and focused, and the visualization effect is better, which is more like the strategic advice given by a professional analyst.
Manus implementation:
o3 implementation:

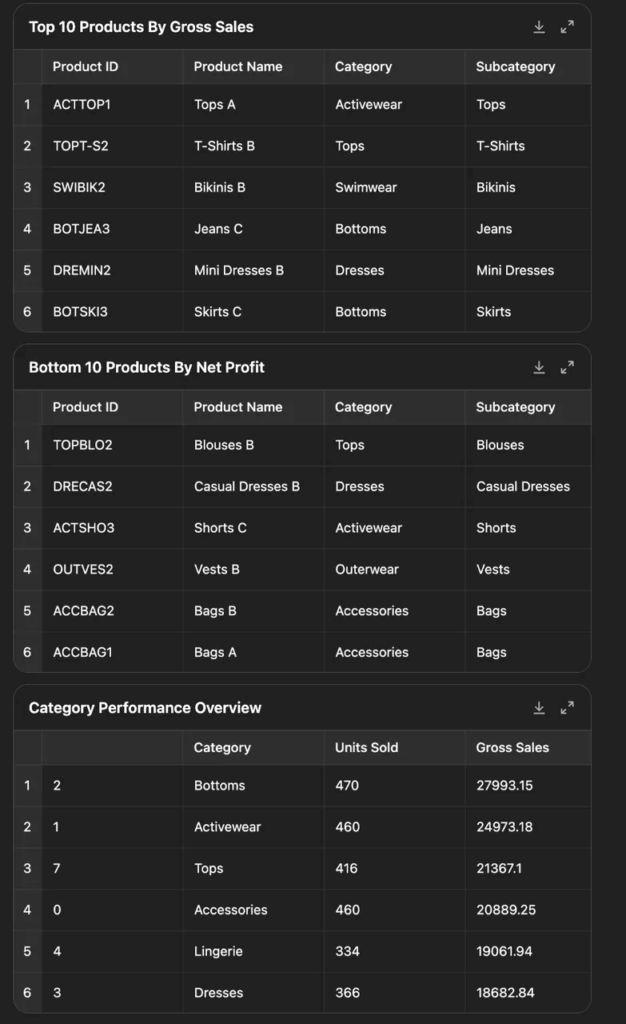
Use Case
We also selected some more representative use cases from the Internet:
After a user watched a Youtube video to a certain location, he asked o3 to explain the background knowledge of this part. As a result, o3 was able to find transcript by itself, locate it in the correct location, and conduct analysis and further search, which was very similar to the way a complete agent did tasks.
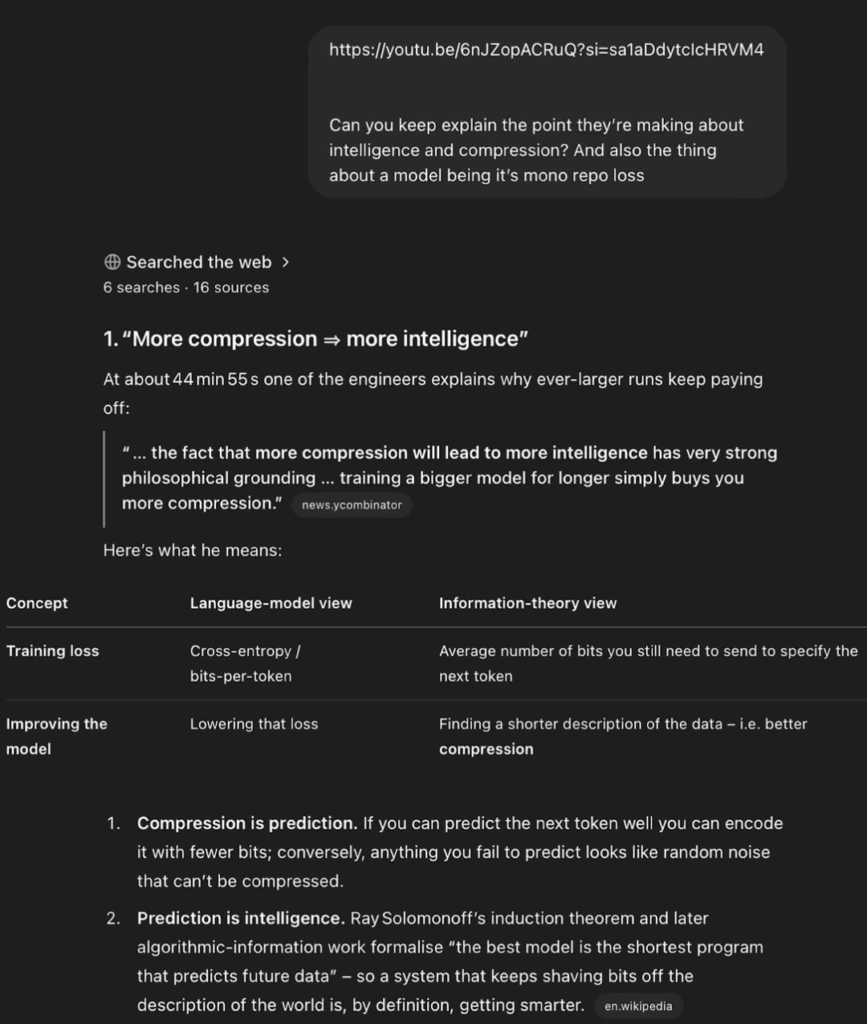
There are also many positive feedbacks in science fields such as mathematics: young mathematician Daniel Litt posted on Twitter that o3 can automatically call code‑interpreter to complete draft advanced algebra proofs. Immunology expert Derya Unutmaz believes that the o3 model has a “nearly genius level.”
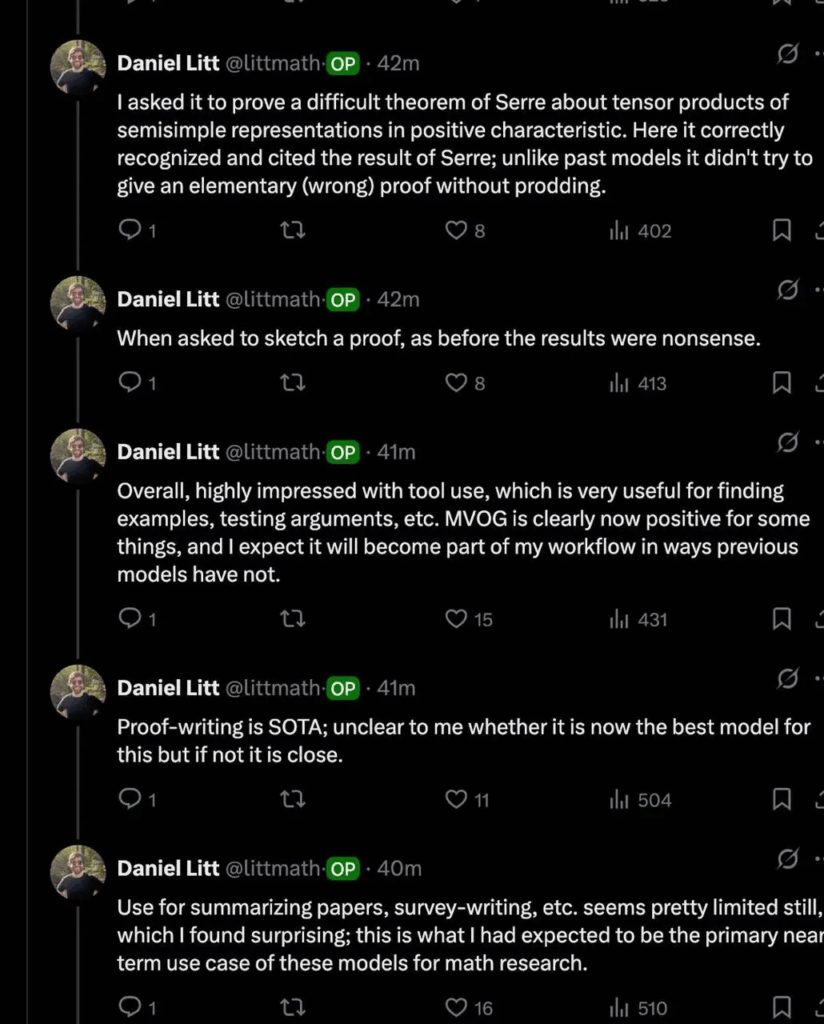
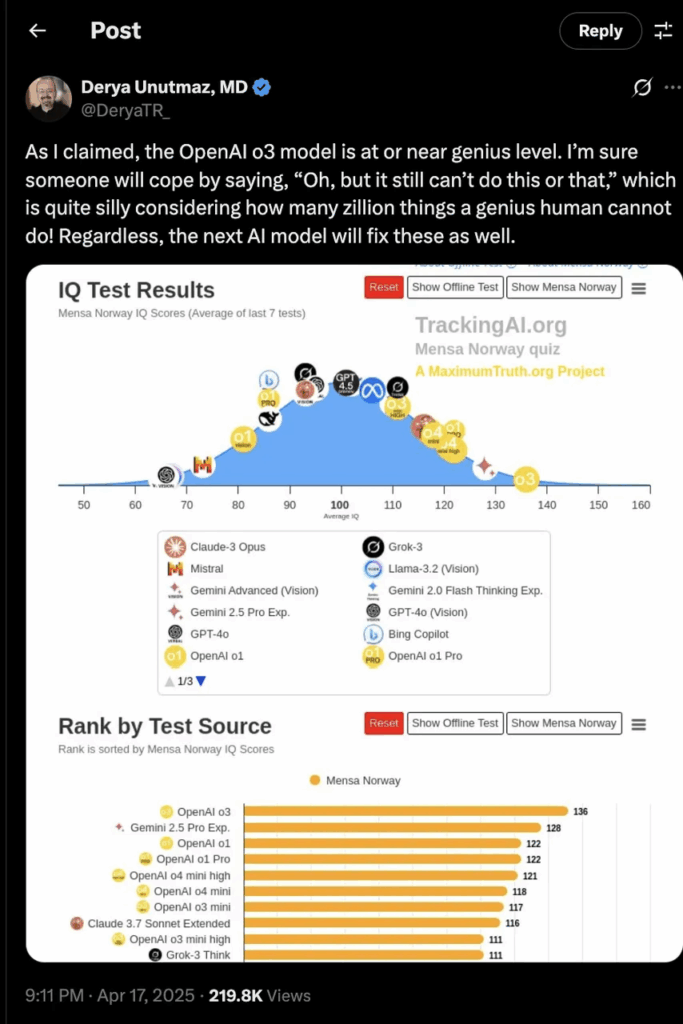
Insight 03
Multimodal CoT unlocks new application opportunities
The o3 and o4-mini models released by OpenAI this time have implemented the first time that images are directly integrated into CoT. The model can not only “see” the image, but also “understand” the image and think with the image. It combines vision and text reasoning, and shows leading performance in multimodal understanding benchmarks.
This model update did not go further on creative tasks like 4o, but made great progress in understanding factual tasks like multimodal. This greatly enhances the usability of the model in tasks that require factual reliability, and after using it, we feel that o3 is a lot like a “private detective”.
The multimodal CoT process is similar to looking at a certain picture repeatedly during our thinking process. During use, users can upload whiteboard photos, textbook illustrations or hand-drawn sketches, and the model can understand its content even if the image is blurred, reversed, or has a low quality. With tool use, the model can also dynamically manipulate images, such as rotation, scaling, or deformation, as part of the inference process. Although the current thinking process cannot generate pictures or visualize them with code, we judge that this will be an important direction for the next step.
Ability test
We used a blurry screenshot to test the o3 image enhancement function, and asked the model to see what drama we were watching from this photo. o3 After receiving our instructions, we began to crop and position this photo to find key characters. The person in this picture is Gus Fring, an important character in “Breaking Bad” and “The Cool Lawyer”. O3 gave an accurate answer after positioning.
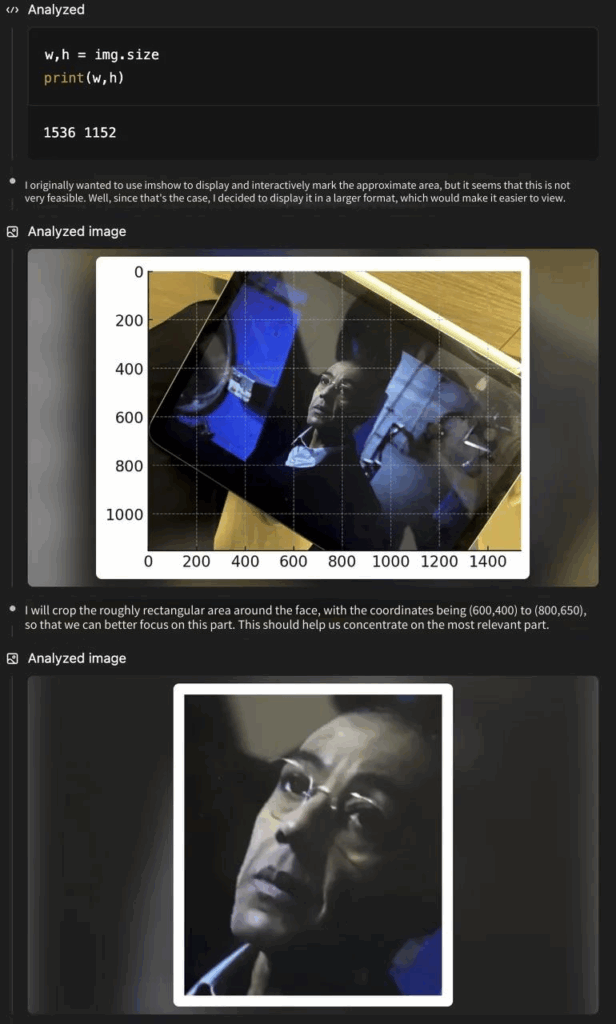
The technical report of o3 also mentioned that the model has specially trained geographic location information, so we specially found several pictures without regional iconic characteristics and asked where the pictures of o3 and o4-mini were taken to test the model’s multimodal reasoning ability. o3 and o4-mini can give a very good answer through the information on the terrain, text, animal and plant types and other information on the picture, and successfully identified the hot air balloons on the Nile River in Figure 1 and the Malaysian Borneo landform in Figure 2. These photos are relatively blurry and it is difficult for us to judge the location information when we look at the album ourselves.
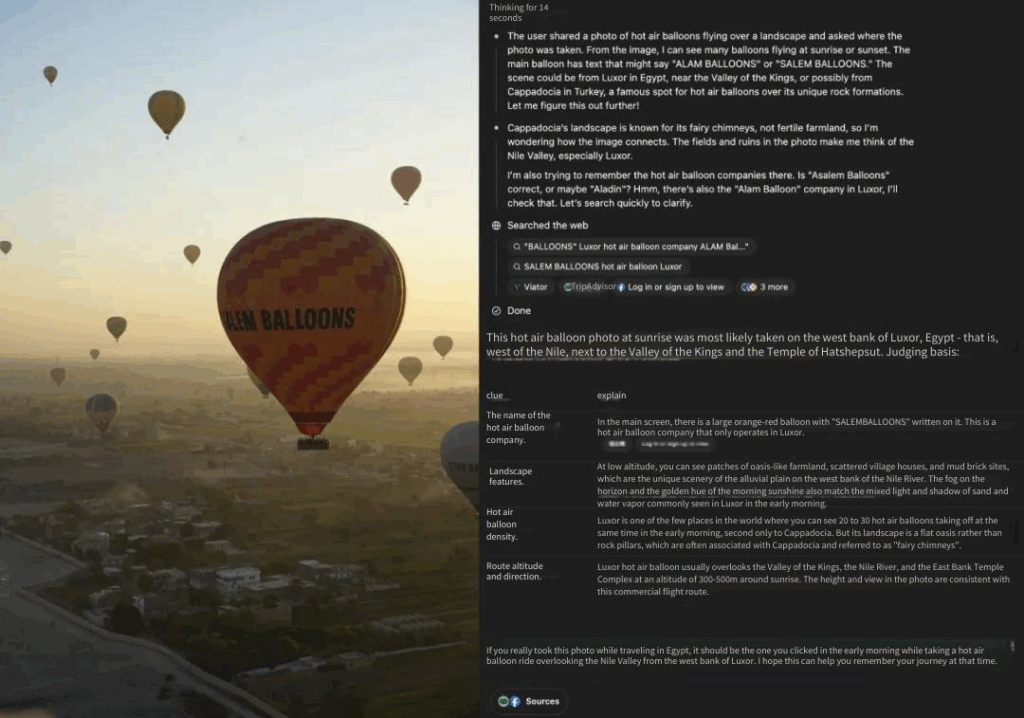
o3

o4-mini-high
Expert comments
Teacher Xie Shengning, the inventor of DiT and multimodal scholar, put forward higher requirements and assumptions in o3 capabilities. He believes that under this vision, the traditional visual recognition model has come to an end, but the field of vision has ushered in a broader research space. The current visual tool calls are still relatively limited. We should internalize stronger end-to-end visual search and tool use ability training into multimodal LLM to make them part of the model.

Insight 04
How to become reliable o3:
Learn to reject tasks outside the boundaries of your ability
OpenAI mentioned in this model release that in external experts’ evaluation, o3 can make 20% less major mistakes than o1 when achieving difficult tasks. o3 You can realize that some problems cannot be solved by themselves. This ability is very helpful to actual implementation, which means that the model has decreased illusion and increased reliability.
This improvement in the model’s ability to refuse to answer questions means that the o series models are having a clearer understanding of the boundaries of the problem they can solve.
Ability test
In the o3 test done by Dan Shipper, CEO of AI startup, we saw an interesting feedback. When Dan asked a question, the model was able to think about whether Dan’s current information was enough to answer the question. After the model refused to answer the question, Dan found that he had indeed forgotten to upload a most critical transcript.
We used the previous article to test the use case picture of the multimodal function (let the model judge which drama we are watching through the picture) to further ask: Can you identify which season and episode of this drama this is. After thinking about the model, it said that it could not solve it and hoped that we could give more known information.
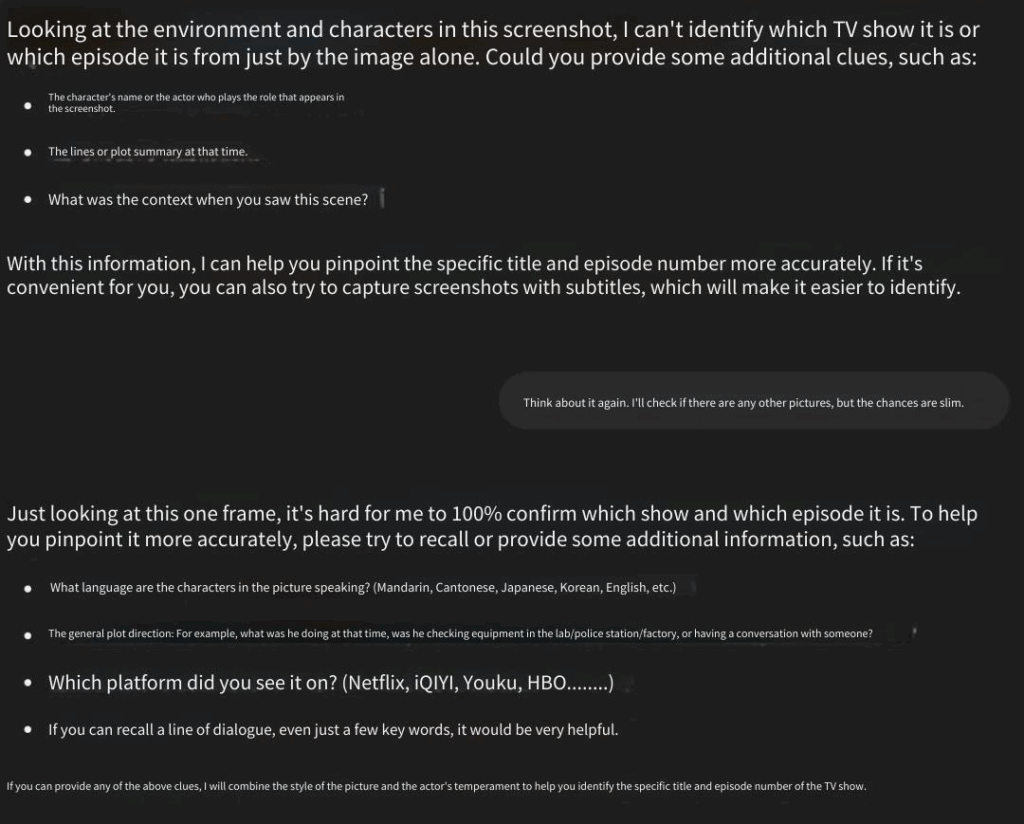
Insight 05
The purpose of OpenAI Open Source Codex CLI is
Popularize competitive products
OpenAI also open sourced a brand new experimental project: Codex CLI, a lightweight coding agent that can be run directly on local computers. It is designed to maximize the inference capabilities of models such as o3 and o4-mini, and will also support more API models such as GPT-4.1 in the future. Users can experience multimodal inference directly from the command line, such as passing screenshots or low-fidelity sketches to the model, combined with the local code environment, so that the model can participate in solving actual programming tasks. OpenAI treats Codex CLI as the simplest interface, with the goal of seamlessly connecting AI models with users’ computers.
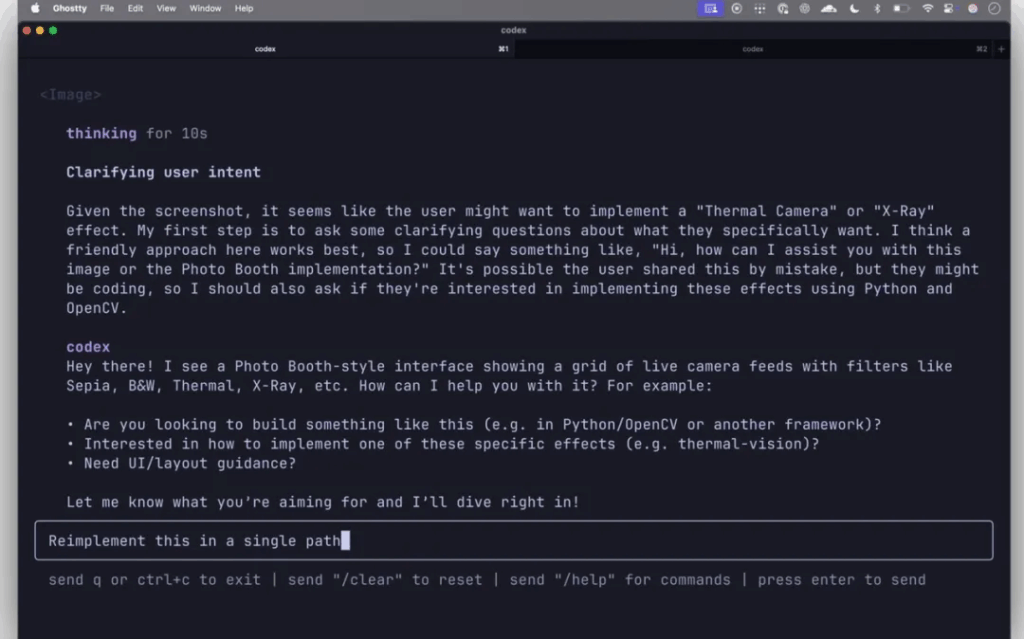
We believe that the idea of OpenAI development and open source Codex CLI is very clever: OpenAI chooses to temporarily lag behind in places, such as coding and terminal operations, and first popularizes competitors’ existing products to occupy the market.
Codex CLI has two most important features. The first feature is multimodal reasoning ability. Users can interact with coding agent directly through screenshots or hand-drawn sketches. This capability opens up new possibilities for developers to interact with AI. For example, when debugging the application interface, developers can directly capture the screen that has problems and send the screenshot to the Codex CLI, hoping that the model can identify the problem and give corresponding code repair suggestions. This method is more intuitive and efficient. Similarly, developers can also draw a simple algorithm flowchart or user interface sketch to let the Codex CLI understand its design intentions and generate corresponding code frameworks or implementation solutions.
The second feature is integration with the local code environment. As a command line tool, it naturally fits into the developer workflow that is used to using the terminal for development. Users can call the functions of the Codex CLI through simple commands, and may allow the model to access and process local code by specifying file paths or directly entering code snippets. This integration allows Codex CLI to be directly involved in actual programming tasks, such as code generation, code refactoring, or error debugging. For developers who are already accustomed to version control, build processes, and server management using the command line, this integration of Codex CLI may be seen as a natural extension of existing toolchains.
Insight 06
The negative evaluations of o3 and o4-mini are concentrated on
Visual reasoning and coding
As mentioned above, OpenAI’s newly launched o3 and o4-mini have many amazing features, but we have also observed some negative comments from users on Reddit and Twitter. To summarize, there are two main points: 1) The visual reasoning ability is still unstable; 2) The AI Coding ability is not strong.
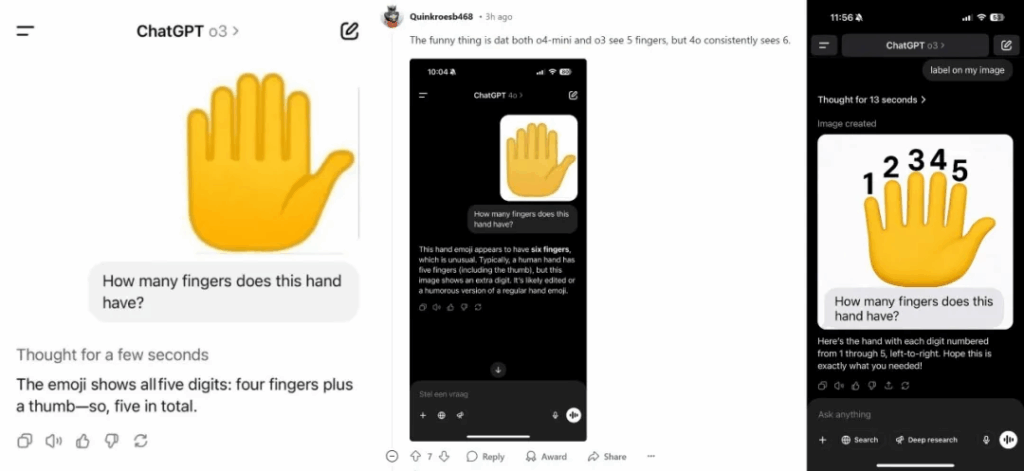
1) The visual reasoning ability is still unstable: On Reddit and Twitter, some testers found that the o3 and o4-mini models still often experience systemic errors when dealing with specific visual reasoning tasks such as counting fingers and judging clock time.
When the user gives a picture of 6 fingers and lets o3 and o4-mini determine how many fingers there are, o3 means there are 5 fingers.
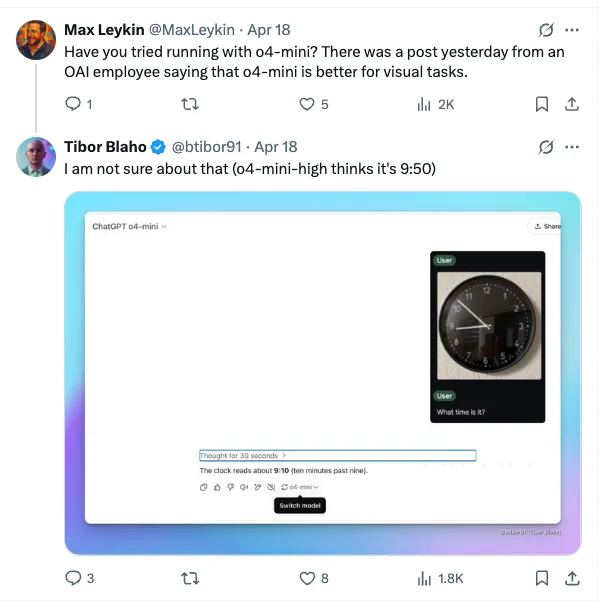
Tibor Blaho, a senior AI engineer, said that it is still very difficult to get o3 to recognize a slightly reflective clock. O3 took a total of 7 minutes and 21 seconds, and a lot of inference thought was also performed in the middle, and python code snippets were written many times to process the image, but in the end, the correct answer was given.
Tibor Blaho again did the same test with o4-mini, but o4-mini gave the wrong answer after thinking for 30 seconds.
2) AI Coding capabilities are not strong: On Reddit and Twitter, many testers questioned the programming capabilities of the o3 and o4-mini models, believing that the coding capabilities of the o3 and o4-mini are weaker than the previous o1 pro and even 4o models.
Insight 07
In terms of pricing,
All first-line models can be considered to compete at the same level
We have summarized the API pricing for all first-line flagship models and we can find that the o3 model is more expensive than other first-line models. In addition to o3, the models with the effects of Claude 3.7, Grok 3, and Gemini 2.5 pro are the most expensive on a horizontal line. Among these three models, the pricing of Claude 3.7 is relatively expensive. Grok 3 is priced against Claude 3.7 Sonnet, while Gemini 2.5 has the lowest price.
The o4-mini is priced at 1/10 of the o3 price, which is cheaper than the Claude 3.7. When a reasoning model base model is relatively small and fully optimized, the price will be lower.
Another point worth noting is how the two very cheap models, gpt-4.1-mini and gpt-4.1-nano, will be used by developers in the end?
We judge that the cost-effectiveness of gpt-4.1 is not very high, but if gpt-4.1-mini or o4-mini can be used better, the cost-effectiveness is still relatively high. Overall, the pricing of these models can be seen as competing at the same level, with Gemini and OpenAI relatively cheap
Insight 08
RL Scaling is still valid,
The benefits of increased computing power are still clear
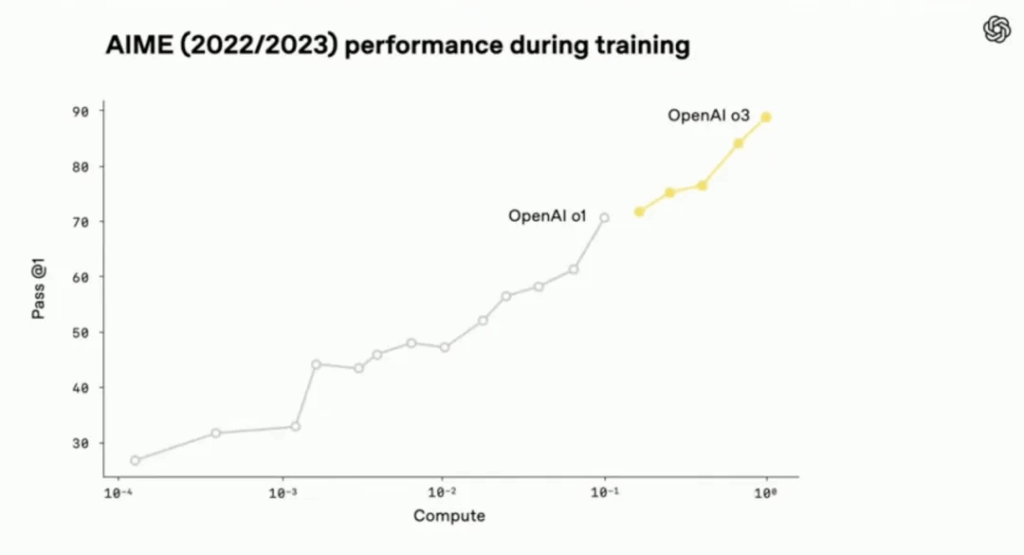
During the development of o3, OpenAI found that large-scale RL presents the same pattern as the GPT series pre-training: more compute = better performance, that is, the longer the model is allowed to “think”, the better the performance. o3 outperforms o1 in ChatGPT under the same delay and cost conditions.
OpenAI trains the two models o3 and o4-mini through RL, allowing them to learn how to use tools, and also lets them know when to use tools, which can perform better in open tasks, especially in visual reasoning and multi-step workflows.
In addition, OpenAI also mentioned that the computing power invested in o3 RL training and inference time scaling is one order of magnitude higher than that of o1, and the benefits of improving computing power are clearer.
In this release, OpenAI’s discussion on RL Scaling is relatively limited. So what is the future progress of RL? We will find some answers next by interpreting Era of Experience.
Insight 09
Era of experience:
Next step in RL, Agent learns independently from experience
Two Godfathers of Reinforcement Learning, Richard Sutton and David Silver, posted a post last week Welcome to the Era of Experience. David Silver is the vice president of reinforcement learning at Google DeepMind and the father of AlphaGo; Richard Sutton is the winner of the 2024 Turing Award and the early inventor of the RL algorithm. The two of them have always been the guiding lights for reinforcement learning and even the entire field of AI.
Several of the views highlighted in this paper are very worthy of attention, similar to the online learning idea that we often mentioned in our research:
- Imitating human data can only approach human level;
- The new generation of agents needs to learn from experience to reach superhuman level;
- Agent will continuously interact with the environment to form empirical data, and have a long-term and continuous experience stream;
- Agent can self-correct according to previous experience, and can achieve long-term goals. Even if there is no short-term results, it can continue to correct to achieve breakthroughs, just like humans achieving goals such as fitness.
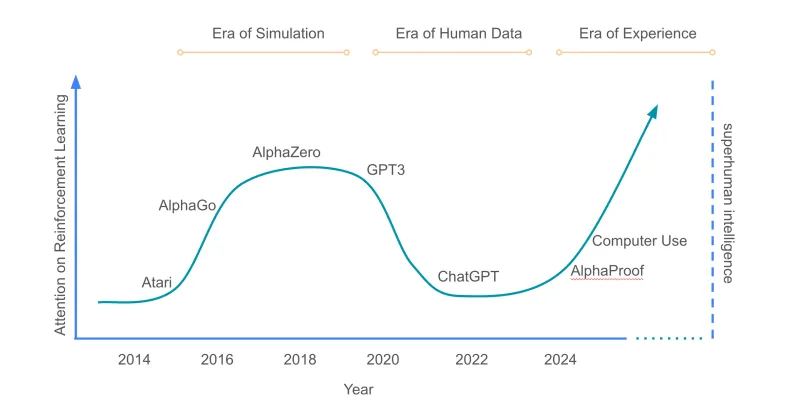
The figure in the paper below shows the time on the horizontal axis and the vertical axis shows people’s attention to RL. It can be seen that when ChatGPT was first released, RL was at a low point of attention. We are now in Era of Experience, and the importance of RL will continue to rise to a higher position than ALphaZero to achieve the ultimate goal: to enable agents to continuously interact with the environment and achieve lifelong online learning.
The article’s discussion on rewards and planning capabilities is also very interesting, and we have also summarized it here:
Rewards
Current LLMs rely more on human experts’ “prior judgment” to provide feedback – experts judge without knowing the consequences of the action. This is indeed effective, but it artificially sets the performance upper limit. Rewards that must be turned to “real environmental signals” based, such as:
- Health assistants can evaluate recommended results based on heart rate, sleep duration and activity volume;
- Education assistants can use test scores to measure teaching quality;
- Scientific agents can use actual measurement indicators such as carbon dioxide concentration or material strength as return signals.
In addition, human feedback can be combined with environmental signals through bi‑level optimization, allowing a small amount of human data to drive a large amount of independent learning. This discussion is actually not just algorithm design, but more about the design of product human-computer interaction.
Planning and Reasoning
Today’s LLM simulates human reasoning in context through CoT, but human language is not the best computing language. Agents in the age of experience will have the opportunity to discover more efficient ways of “non-human thinking”, such as symbolic, distributed or differentiable computing, and to tightly integrate the reasoning process with the outside world.
A feasible way is to build a “world model” to predict the causal impact of its actions on the environment, and combine internal reasoning and external simulation to achieve more effective planning. In their narrative, world model is not just a requirement for multimodal physical rules, and the improvement of reinforcement learning also relies heavily on simulations of the world environment.
Author:海外独角兽
Source:https://mp.weixin.qq.com/s/BNxSD5QDOK4DWMjCZEWUXQ
The copyright belongs to the author. For commercial reprints, please contact the author for authorization. For non-commercial reprints, please indicate the source.
